[Paper Review] WAV2VEC: Unsupervised Pre-training for Speech Recognition
제발 틀린거 있으면 피드백 주세요.
논문 링크(Arxiv)
FAIR에서 낸 논문인데, 한줄요약하자면 그냥 raw audio에서 기존에 막 spectrogram그리고 뭐 해서 피처 뽑는거보다 CNN써서 피처 뽑는게 훨씬 낫다. 근데 그 피처를 뽑아주는 모델을 Word2vec처럼 학습했다. 나도 FAIR갈래.
AIM: Speech Recognition계의 BERT를 만들어 보자. (근데 사실word2vec임)
옆동네 BERT가 대박친거처럼 SLP에도 downstream task의 성능을 올리는데 도움을 줄 수 있는 pre-trained model이 있으면 참 좋지 않겠습니까? 데이터에 레이블이 다 있으면 end-to-end로 학습 시킬 수 있겠지만 그렇게 resource가 많은 것도 아니고.. 일단 speech data 자체의 general representation을 학습할 수 있나 봅시다요.
Overview
CNN 기반의 Wav2Vec이라는 모델을 제안한다.
- 인풋: raw 오디오파일
- 아웃풋: Speech Recognition System에 넣을 수 있게 잘 정리된 오디오의 general representation
Wav2Vec이 학습되는 방법: Negative sample 사이에서 positive sample을 뽑는 방식으로, 앞으로 올 오디오 데이터를 예측하는 문제를 풀면서 representation을 학습하자. (word2vec에서 negative sampling 방식을 생각하면 됩니다.)
기존 연구와 다른점: 기존에는 phoneme classification을 위해서 frame-wise로 오디오 파일을 봤다면, 이 논문에서는 바로 latent representation을 활용해서 ASR 시스템에 적용함. 또한, RNN기반의 기존 연구와는 다르게 CNN기반이라서 병렬처리가 수월하다.
Model
Raw audio상에서 미래에 어떠한 시그널이 올지 예측하기 위해서는 raw audio space에서 데이터의 분포 \(p(x)\)를 알아야 하는데, 이는 너무 어렵기 때문에 저차원의 latent space에서 density ratio를 모델링 하는 방향으로 접근한다. z를 latent representation이라고 했을 때 수식으로는 아래와 같다. (별다른 뜻은 없음.)
\[p(z_{i+k} \mid z_{i}, \cdots, z_{i-r})/p(z_{i+k})\]이를 위해 크게 encoder network와 context network를 만들었다. 큰 그림으로는 아래와 같은 transformation을 거치는 것이다. X는 raw audio space, Z는 latent space, C는 context space를 나타낸다.
\[\mathcal{X}\mapsto\mathcal{Z}\mapsto\mathcal{C}\]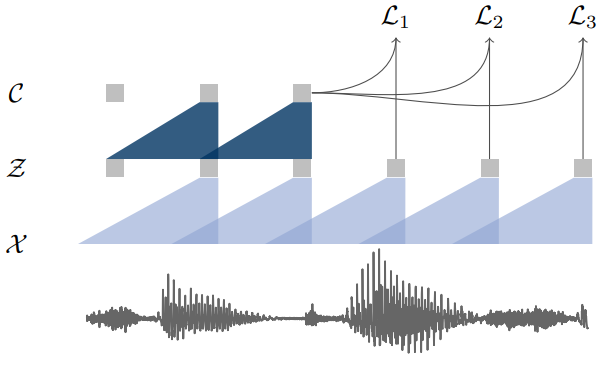
- Encoder network (\(f: \mathcal{X}\mapsto\mathcal{Z}\))
Lower temporal frequency domain으로 보내기 위한 network. 논문에서는 5층짜리 CNN을 썼고, 디테일은 커널 사이즈 (10,8,4,4,4), 스트라이드 (5,4,2,2,2)이다. 이런식으로 인코딩을 하면 16kHz 샘플링 레이트 기준으로 30ms정도의 오디오가 latent representation z에 반영되며, 10ms정도의 스트라이드를 갖는다.
- Context network (\(g: \mathcal{Z}\mapsto\mathcal{C}\))
위 encoder network를 거쳐서 나온 latent representation을 contextualized tensor로 매핑해주는 network. 9층짜리 CNN을 썼고, 모두 커널 사이즈 3에 스트라이드 1짜리 필터를 사용했다. Latent representation c 의 receptive field는 210ms정도가 된다.
두 network에 사용된 convolution filter는 전부 causal이며 (다음 레이어에 미래의 값이 들어가지 않는 형태. 그림1과 같이 현재 representation은 과거의 시그널로만 만들어진다.) 512채널을 사용했다. Group normalization과 ReLU를 사용하였는데, normalization을 할 때 스케일과 인풋 offset에 로버스트한 normalization방법을 택하는 것의 중요성을 강조하였다. 해당 논문에서는 instance normalization을 사용하였다. (feature와 time방향으로 모두 normalization을 진행한 것.)
더 큰 데이터셋에서 학습할 때는(wav2vec large) 모델에 층을 늘리고 커널 사이즈도 늘려서 context layer의 receptive field가 810ms정도가 되었다.
Loss function
손실 함수의 수식을 먼저 보면 다음과 같다.
\[\mathcal{L}_k = - \sum_{i=1}^{T-k}\Big( log\sigma(\bold{z}^\top_{i+k}h_k(c_i)) + \lambda\mathbb{E}_{\widetilde{\bold{z}} \sim p_n}[log\sigma(-\widetilde{\bold{z}}^\top h_k(c_i))] \Big)\]위에서 언급한 것과 같이 negative sample 가운데서 positive sample을 가려내는 과정이 담겨 있다. 모두 latent space에서 진행된다.
- \[k\]
k는 얼마나 뒤의 오디오 시그널을 예측할지를 나타내는 변수로, 실제 학습시에는 여러 k를 두고 각 k에 해당하는 손실 함수의 합을 최소화 하는 방향으로 모델을 학습한다.
- \[z\]
\(\tilde{z}\)는 distractor sample, 즉 negative sample이고 이 가운데서 \(z_{i+k}\)라는 k-step후의 positive sample을 가려내는 것이다. \(\sum\) 안에 있는 표현 중 첫번째 항은 \(z\)가 positive sample일 확률, 두번째는 \(\tilde{z}\)들이 negative sample일 확률의 기댓값을 표현한다고 생각하면 되는 것이다. (\(\sigma\)는 sigmoid) 실제로는 기댓값을 알 수 없기 때문에 negative sample을 10개 추출하여 평균을 구함.
- \[p_n\]
Negative sample은 현재 보고 있는 오디오 파일 내 에서 추출하며, 추출하는 분포는 uniform random(1/T) 분포이다. (T는 sequence 길이다. 다른 파일에서 추출하는 경우 결과가 안좋았다고 한다.)
- \[h\]
h는 아래와 같이 context time step i 에서의 affine transformation이다. k마다 한개의 h가 있으며, k 스텝 뒤의 z를 예측하는 데 쓰인다. (FC layer 한개라고 생각하면 된다.)
\[h_k(\bold{c}_i) = W_k\bold{c}_i+\bold{b_k}\]- \[\lambda\]
람다는 Negative Sample의 개수 이다.
Experiment
Wav2vec의 우월성을 검증하기 위해 ASR task를 진행하고, 최종 metric은 WER(Word Error Rate)와 LER(Letter Error Rate)을 사용하였다. 베이스라인 모델은 80 log-mel filterbank coefficient를 input으로 가지며, wav2vec의 경우와 같은 downstream network 구조를 가지고 있다. 즉, 오디오의 임베딩만 다르게 설정하여 얼마나 downstream network의 학습이 잘 되는지를 평가한 것이다. (nlp에서 임베딩 품질을 결정할 때 쓰이는 기법과 비슷하다.)
Data
총 3개의 데이터셋이 사용되었는데, TIMIT, WSJ, Librispeech이다. 모두 16kHz의 샘플링 레이트를 가지고 있는 영어 오디오 데이터이다.
Acoustic Models (Downstream model)
베이스라인과 wav2vec이 공유하는 downstream model에 대한 설명.
TIMIT과 WSJ에 대해서 각각 다른 네트워크를 사용하였고, TIMIT의 경우에는 CNN 7층, 1000채널, 커널 사이즈 5, PReLU와 droupout 0.7을 사용하여 최종 층에서 39차원짜리 phoneme probability를 반환하는 형태로 가져갔다. 자세한 것은 [4]논문을 참고하면 된다.
WSJ의 경우는 17층의 gated CNN을 사용하였고, 마지막 층에서 31차원의 확률 벡터를 반환한다. 여기서 특이한 점은 영어발음 뿐 아니라 따옴표나 마침표, 침묵 토큰(‘|‘로 표기) 등을 함께 사용하였다는 점이다. 자세한 사항은 [3]논문을 참고하면 된다.
위의 모델에서 나온 결과를 디코딩하기 위해서 lexicon과 더불어 WSJ에서 학습된 언어모델을 사용했다. 그것은 4-gram KenLM, 단어기반 convolutional 언어모델, 캐릭터기반 convolution 언어모델으로 총 4가지의 디코딩 모델을 사용한 것이다. (디코딩에 대해서 추가 예정. 결국 위 모델에서 나온 phoneme을 어떻게 language model 문제로 바꿔서 보여줄 수 있느냐의 문제인 것 같음. 참조)
Training Details
Downstream Models
두 모델 모두 NVIDIA V100 GPU 8대를 사용하였으며, fairseq과 wav2letter++[5]를 사용하여 분산 학습을 진행하였다. TIMIT의 경우는 모멘텀 SGD, batch 16을, WSJ는 바닐라 SGD와 gradient clipping, batch 64를 사용하였다. 두 모델 다 1000 에폭씩 학습했다. 또한, 4-gram 언어 모델로 체크포인트를 설정하고 검증셋의 WER를 기반으로 early stopping을 진행하였다.
Pretrained Models
Pytorch fairseq으로 구현하였고, Adam과 cosine learning rate schedule을 사용하였다. Pretrained model의 경우는 WSJ과 Librispeech를 사용하였는데, WSJ + clean Librispeech를 사용하거나 full Librispeech를 사용하였다. Librispeech는 WER이 낮은 ‘clean’ 데이터와 WER이 높은 ‘other’ 데이터를 모두 포함한다. (WER이 높다는 것은 언어-우리 경우에는 영어-의 전달력이 낮다는 뜻.)
손실 함수 계산을 위해서는 negative sample 10개를 추출하였고, K는 12로 설정하였다. 즉, 1스텝 후, 2스텝 후, … 12스텝 후의 latent representation을 예측하는 손실 함수를 계산하여 합을 구한 것이다.
역시 위와 같은 GPU 8대를 사용하여 학습하였고, 한 GPU에 1.5M의 오디오 frame이 올려져 학습을 진행했다. 먼저 데이터를 길이에 따라 grouping 하였고, 각 그룹 안에 있는 각 데이터가 frame이 150k를 넘지 않도록 했다. 해당 그룹에 150k보다 작은 데이터가 있을 경우 그 데이터의 모양에 맞춰서 다른 모든 데이터를 잘랐다. 잘라야하는 경우에는 랜덤하게 오디오의 앞쪽이나 뒤쪽에서 적절히 crop했다. 총 데이터의 25%가 잘려져 나갔고, 모든 GPU에 올려져 있는 배치 데이터는 약 556초의 오디오이다. Large 모델의 학습에는 GPU를 16대 사용하였다.
Results
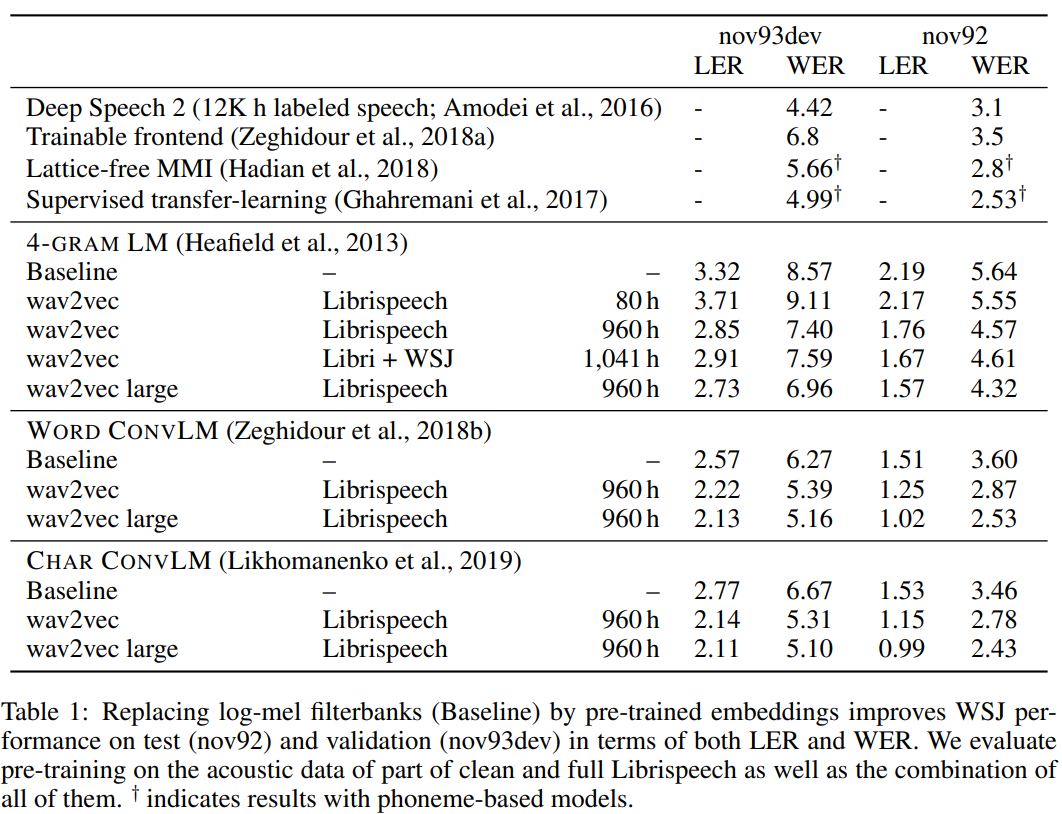
위의 테이블이 가장 큰 결과이다. 결국에는 pretrained 모델을 썼을 때, 그리고 pretrained model에 쓰이는 데이터가 많을수록 더 성능이 잘나온다는 것이다.
논문의 뒷부분은 모델의 hyperparamter 선정에 관한 부분이다. Negative sample의 개수 (10개), data augmentation할 때 150k를 고른 이유, 그리고 손실함수 계산 시 K = 12 모두 학습시간과 성능을 고려했을 때 가장 좋은 결정이었다는 점을 설명함.
My Conclusion
멋있다. 음성데이터를 어떻게 인코딩해야할지 감이 안잡혔었는데 페이스북 역시.. 프리트레인모델 써서 시도하고 싶은 것이 생겼다.
같이 읽어야 하는 논문
[1] Wav2Letter: an End-to-End ConvNet-based Speech Recognition System
[2] Representation Learning with Contrastive Predictive Coding
[3] A FULLY DIFFERENTIABLE BEAM SEARCH DECODER
[4] End-to-End Speech Recognition From the Raw Waveform
[5] WAV2LETTER++: THE FASTEST OPEN-SOURCE SPEECH RECOGNITION SYSTEM
Leave a comment