[Paper Review] Model-based Reinforcement Learning for Predictions and Control for Limit Order Books
제발 틀린거 있으면 피드백 주세요.
논문 링크(Arxiv)
JP Morgan 연구진이 AAAI에 발표한 논문. LOB 데이터로 RL agent를 학습시켰는데, 신기하게도 market microstructure를 통째로 모델링하여 그 모델을 기반으로 agent를 만들었다. 내가 알고리즘을 구현 할 수 있을까는 둘째치고 이 데이터와 컴퓨팅파워가 현실적인 것인가 생각하다가 생각하는 시간이 아까워서 그냥 읽음. 시작
Introduction
보통 RL을 사용해서 게임을 기가 막히게 할 수 있는 agent를 만든다. 왜 게임에 이렇게 많은 agent가 만들어지는걸까? 기본적으로 RL은 trial and error기반이기 때문에 현실적으로 여러번 시도해서 피드백을 받을 수 있는 도메인이 있다면 비교적 손쉽게 agent를 학습 시킬 수 있다. 그런데 게임이 아니고서야 실제 환경에서는 취할 수 있는 모든 행동을 무한정으로 시도하기가 어렵다. 자율주행 차 같은 걸 학습 시키려면 피드백을 받기 위해 몇대의 차를 부숴먹어야 하는지 생각해볼 수 있다. 이런 문제 때문에 agent가 상호작용하는 환경(environment - RL용어임)을 모델링해서 일종의 시뮬레이터를 만드는 방법을 사용한다. 이번 논문에서도, 여러번 실제 주식을 사고팔고 해서 trial and error 방식으로 돈버는 방법을 학습하면 참 좋겠지만은.. $가 모자라기 때문에 시장을 모델링 하고 그 모델 안에서 안전하게 agent를 학습 시킨다. 정말 안전하다.
그럼 기존의 트레이더는 어떻게 전략을 세우고 시장에서 그 전략을 사용해왔을까? 먼저는 트레이더의 경험과 도메인 지식을 반영한 1. 거래전략과, 그 거래전략의 백테스팅을 위해 필요한 2. 시장 상황을 예측하는 시뮬레이터가 필수적이다. 특히 2번의 시장 시뮬레이터에서는 통계적인 기법을 사용해 시계열 데이터를 생성해내거나 머신러닝 방법론을 통해 시장 상황을 예측 해왔던 것이다. 하지만 이런 방법은 시뮬레이터의 오류가 쌓이고 전략이 커버하기 힘든 extreme한 상황이 나온다면 그 단점을 극적으로 노출하게 된다. Explicit하게 시장을 예측하고 heuristic에 의존하여 전략을 디자인한 결과이다.
이를 타개하기 위해 호가데이터를 사용해 직접적으로 거래전략을 학습하는 RL agent를 만드려는 시도가 있었는데, 대다수의 경우 위의 1. 거래전략을 자동으로, 또 최적으로 수행하는 agent만을 만든 것이지, 이 agent를 테스트하기 위해서 사용한 시뮬레이터는 전통적인 시뮬레이터를 사용했다는 단점이 있었다. 이 논문에서는 그 두가지를 모두 데이터에 기반해 학습할 수 있는 방법을 제시한다.
- State space뿐 아니라 reward도 같이 모델링하기 위해 latent representation learning을 이용하였다.
- 이 모델에서 거래전략을 학습한 RL agent는 실제로 좋은 성적($)을 보였다.
Background
짧게 3가지 개념을 살펴보자.
-
호가 (LOB, Limit Order Book)
특정 시각(\(t\))에서, 해당 주식을 몇주(\(bs(t)\))나 얼마(\(bp(t)\))에 사고(bid), 몇주(\(as(t)\))나 얼마(\(ap(t)\))에 팔고(ask)자 낸 주문이 각 가격대에 몇 주문이나 되는지를 기록한 것이 호가 데이터이다. 뭐 대충 이렇게 생겼다.
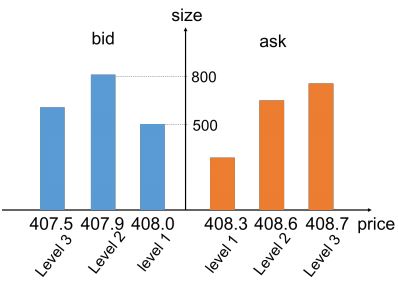
-
중간가격 (Mid Price)
가장 싼 팔자주문과 가장 비싼 사자주문을 각각 최우선매도호가, 최우선매수호가 등으로 부르는데, 중간가격은 그 두 최우선 호가의 평균값이다. 즉, 직관적으로 생각했을 때 시장이 가장 합리적이라고 판단한 가격이라고 할 수 있다. 이 논문에선 reward를 설계하는 데에 이 중간가격을 사용하였다.
-
체결 (Trade Prints)
만약 사자 주문과 팔자 주문이 같은 가격에서 만난다면 거래가 체결되게 되는데, 얼마에 어느 양이 체결되었는지의 데이터가 체결데이터인 것이다. 본 논문에서는 체결 데이터를 흥미롭게 사용했다. RL agent가 택할 수 있는 action의 한 가지로도 보고, 그 agent가 처한 state에도 포함시킨 것이다. 학습하고자 하는 agent의 경쟁자가 한 행동이기 때문에 택할 수 있는 action으로도 보고, 관찰하는 state로도 본 것이다.
Problem Formulation
MDP
강화학습을 통해 풀고자 하는 문제인 만큼, 문제를 MDP 프레임워크에 맞추어 정의한다. (\(\mathcal{S,A,R,T,}\rho_{0}\))
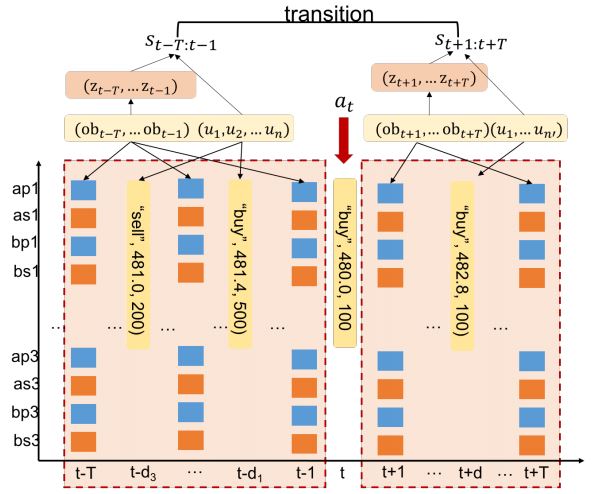
- State space (\(\mathcal{S}\)): \(s_{t} = \{z_{t}, u_{t}, po_{t}\}\)
\(z_{t} = ae(ob_{t-T:t})\): \(T\)시간동안의 호가 데이터의 latent representation. 밑에 나올 시장 상황의 인코딩 정보이다.
\(u_{t}\): \(T\)시간동안 일어난 모든 trade prints 데이터
\(po_{t}\): 시각 \(t\)에 RL agent의 포지션. 해당 주식을 얼마나 들고있느냐. \((-po_{max}, po_{max})\)로 유계임.
- Action space (\(\mathcal{A}\)): \(a_{t} = \pm q\)
\(t\) 시각에서 내리는 결정. 해당 주식을 얼마나(\(q\)) 살거냐(팔거냐)로, 모든 가격은 위에서 정의한 중간가격으로 한다.
- Reward function (\(\mathcal{R}\)): \(\Delta mid_{s_{t},s_{t+1}} \times po_{t}\)
\(t\)와 \(t+1\)사이에 버는 돈. (단순 PnL) \(\Delta mid_{s_{t},s_{t+1}}\)는 상태 \(s_{t}\)와 \(s_{t+1}\)에 해당하는 평균중간가격의 차이를 나타내고 그 가격 차이만큼 RL agent의 포지션(\(po_{t}\))을 곱해서 계산한다.
- Transitions (\(\mathcal{T}(s_{t+1} \mid s_{t},a_{t})\))
과거 데이터에서 볼 수 있는 상태 전이 궤적을 보고 환경 모델을 훈련한다. 특히 체결 데이터에 집중해서, 전이에 사용되는 action으로 체결 이벤트를 사용한다. 다음 상태로 옮겨갔을 때 그 같은 action이 상태의 일부분으로 편입될 수도 있다. (위 사진 참조)
- Initial state (\(\rho_{0}\))
초기상태는 상태 데이터셋에서 균등분포로 샘플링했다.
Data
홍콩증권거래소에 상장된 주식 1개의 호가 데이터를 사용했다. 2018년 1월부터 2018년 3월 사이(61일)에 해당하는 데이터를 학습데이터로, 2018년 4월(19일)에 해당하는 데이터를 모델 성능 평가를 위해 썼다. 0.17초에 1건의 데이터가 기록되어, 학습 데이터셋 6백만개 테스트셋 2백만개, 총 8백만개의 데이터를 사용했다. 피처 노말라이즈를 했고 호가는 주문량이 100주와 1000주 사이인 주문만 걸러서 노말라이즈 했다고 한다. Reward값은 학습시에만 정규화 후 sigmoid를 씌웠다고 한다.
Model
World Model
시장의 latent representation을 학습하고 시장을 시뮬레이트 하는 모델이다. 아래의 3개 부분으로 이루어진다.
Latent Representation Model (Autoencoder)
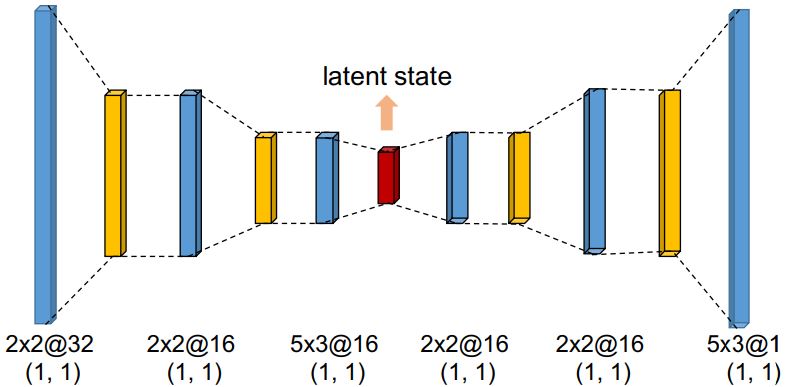
먼저 CNN기반의 오토인코더를 사용해서 호가 데이터를 압축한다. 시계열 시장 데이터는 고차원이고 잡음도 많기 때문에 일단 저차원 representation을 생성하는 것이다. 오토인코더는 인풋(아웃풋)은 \(T \times 4L\)의 아웃풋 차원을 가진다. \(L\)은 차선호가의 레벨로, 매수 매도 각각의 가격과 주문 수량을 나타내기 때문에 \(4L\)이다. 오토인코더의 중간 병목층을 잠재 representation으로 사용하는 것이다.
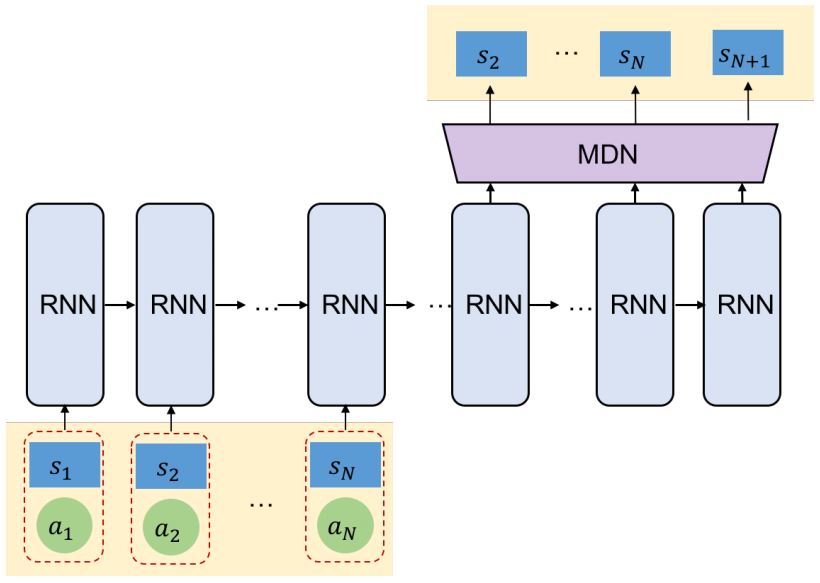
Transition Model (RNN-MDN)
state-action 전이 함수 \(\mathcal{P}(s'|s,a)\)를 모델링한 것이다. 시장이 변하는 것과 주문이 시장에 미치는 영향을 모델링한 것이라고 보면 된다. 먼저 RNN을 사용하여 장단기 영향을 모델링하고 이 RNN을 MDN (Mixture Density Network)과 결합한다. RNN의 결과를 확률분포의 결합으로 추정하는 것이다.
\[p(s'|s,a) = \sum_{k=1}^{K}{w_k(s,a)\mathcal{D}(s'|\mu(s,a),\sigma_{k}^{2}(s,a))}\]여기서 \(\mathcal{D}\)는 가우시안, 베르누이 등 미리 가정하는 분포이다. 아래의 그림처럼 N개의 인풋 state를 받아서 N+1번째의 state를 예측한다.
Reward Model
위 모델을 통해 나온 예측 state와 1단계 전 state를 회귀 모형에 넣어 중간가격의 변화를 예측한다. Reward는 현재 내 position과 중간가격의 변화를 곱한 PnL로 정의되는데, 식은 다음과 같다.
\[r_{t} = \mathcal{R}(z_{t},z_{t+1};\beta) \times po_{t}\]\(po_{t+1}\)은 \(t+1\)시간일 때의 포지션으로, \(t\)의 포지션에다가 \(t+1\)에 취하는 action을 반영하여 계산된다. 식으로 표현하면 아래와 같다.
\[po_{t+1} = \left\{ \begin{array}{cc} min(po_{t}+|a_{t}|,po_{max}) & \text{if} & a_{t} & \gt 0\\ max(po_{t}-|a_{t}|,-po_{max}) & \text{if} & a_{t} & \lt 0\\ \end{array} \right.\]여기서 \(po_{min}\)과 \(po_{max}\)는 각각 포지션의 극값이라고 할 수 있다.
Agent Model
위에서 만든 world model에서 RL agent를 학습시킨다. 초기값은 랜덤하게 정해주고 정해진 시간까지 agent를 계속 학습시킨다. Policy가 수렴하면 백테스팅을 한다. 호가와 체결 정보를 가지고 잠재 representation을 만들어 트레이딩을 시뮬레이션 하는것이다. Agent 학습을 위한 알고리즘은 DDQN, PG, A2C 세가지를 썼다.
DDQN
Double DQN은 뉴럴넷으로 Q값을 추정하는 방법인데, 타깃 Q값을 나타내는 함수와 그 타깃에 맞추어 계속 업데이트 되는 함수가 따로 존재한다. 학습 중에 타깃값이 계속해서 바뀌기 때문에 변동성을 줄이기 위해 타깃 Q를 고정시키고 일정 주기에 맞춰서 업데이트 한다.
\[L(\theta) = \mathbb{E}[(Q(s,a;\theta)-Q_{target})^{2}]\] \[Q_{target} = r + \gamma Q(s',arg \max_{a'}{Q(s',a';\theta)};\theta_{-})\]PG
Policy를 함수로 생각하고 그 모수(\(\theta\))를 직접적으로 추정한다. 그 모수를 최적화하면서 누적 reward를 최대화 하는 것을 목표로 한다. Q-learning에 비해서 value overestimation에 robust하다. 하지만 누적 reward를 계산할 때 policy 분산이 커질 수도 있다는 점은 주의해야한다. \(\theta\)를 바꿔가며 아래의 J를 최대화하는 것이다.
\[J(\theta) = \mathbb{E}_{\tau}[\sum^{H}_{t=0}log\pi(a|s,\theta)G_{\tau}]\] \[G_{t} = \sum^{H}_{t=0}\gamma^{t}t_{t}\]A2C
Value-based와 PG방식을 결합한 것으로, Advantage value(A)를 기반으로 policy를 업데이트하는 Actor(A)와 TD에러에 따라 value를 업데이트 하는 Critic(C)로 이루어졌다. A2개 C한개 해서 A2C이다. Advantage Value를 쓰기때문에 policy분산이 커지지 않는다는 점과, value함수 추정을 통해 policy가 직접적으로 업데이트 된다는 점이 장점으로 꼽힌다.
\[J(\theta) = \mathbb{E}_{\tau}[\sum^{H}_{t=0}log\pi(a|s,\theta)A(s,a)]\] \[A(s_{t},a_{t}) = r_{t}+\gamma V(s_+{t+1};w) - V(s_{t};w)\] \[J(w) = (r_{t} + \gamma V(s_{t+1};w)-V(s_{t};w_{-}))^{2}\]Experiment
Benchmark
위의 방법으로 학습시킨 agent랑 비교할 벤치마크로 다음의 3가지를 사용한다.
Momentum-driven strategy
중간가격 기준으로 한 state내에서 시가와 종가를 비교해서 해당 트렌드가 다음 state에도 지속되는 데에 투자하는 방식이다. 투자 금액은 논문에서 hand-crafted 값을 사용했다고 한다. (값 고정) 가격의 움직임은 상승, 하락, 보합 3가지로 나눠지며 이에 따라서 다음 state에서 매수, 매도, 유지 action을 취하게 되는 것이다.
Classifier-based strategy
다음 state에서 중간가격이 상승, 하락, 보합 중 어느 상태를 보일 것인지를 예측하는 분류기를 학습해 이에 따라 투자하는 방식이다. 3개의 CNN층과 1개의 FC층을 썼다고 한다.
Greedy Optimal
Agent가 미래 상태를 안다고 가정하고 트레이딩을 진행하는 것이다. 당연히 실질적 의미의 벤치마크라기보다는 agent가 이룰 수 있는 성능의 상한을 보여준다고 생각하면 될 것이다. Action을 21개로 이산화한 다음 BFS를 사용하여 최적의 action을 찾는 방식으로 이루어진다. 21개라는 것은 매도 20개, 매수 20개 유지 1개를 나타낸다. 모든 옵션을 다 생각하기에는 가지수가 너무 많기 때문에 greedy search를 사용한다. 서치하는 현 상태 기준으로 가장 좋아보이는 action을 선택하는 것이다. 충분히 납득할 만한 타협점이다.
Results
2%의 수수료를 가정하고, 데이터 중 4일의 호가 데이터를 무작위로 선정해서 위 벤치마크와 학습시킨 RL agent를 테스트한 결과이다. RL agent는 다른 벤치마크보다 더 greedy optimal에 가까운 결과를 냈고, 사용한 RL 알고리즘 중에서는 A2C가 다른 두개의 알고리즘보다 성능이 좋았다고 한다. 분류기 기반 전략은 상당히 성적이 안좋았는데, 보합에 너무 가중치를 줘서 실제로 액션을 취하는 스테이트가 많이 없었다고. 근데 어떻게 보면 이해가 되는게 금융시장은 애초에 짧은 시간 내에서는 그렇게 많은 변동성이 없다. 그리고 랜덤워크 성향이 강해서 이전 상태를 그대로 예측하는 것이 가장 좋은 예측방법이라고 생각하는 이론도 있을 정도다. (마팅게일) 이를 위해서 1개의 state에 해당되는 시간을 늘릴 수 있겠지만 state 1개당 1개의 action을 취하는 RL agent특성상 agent의 granulity가 많이 줄어들게 되는 것이 문제점이라고 할 수 있다.
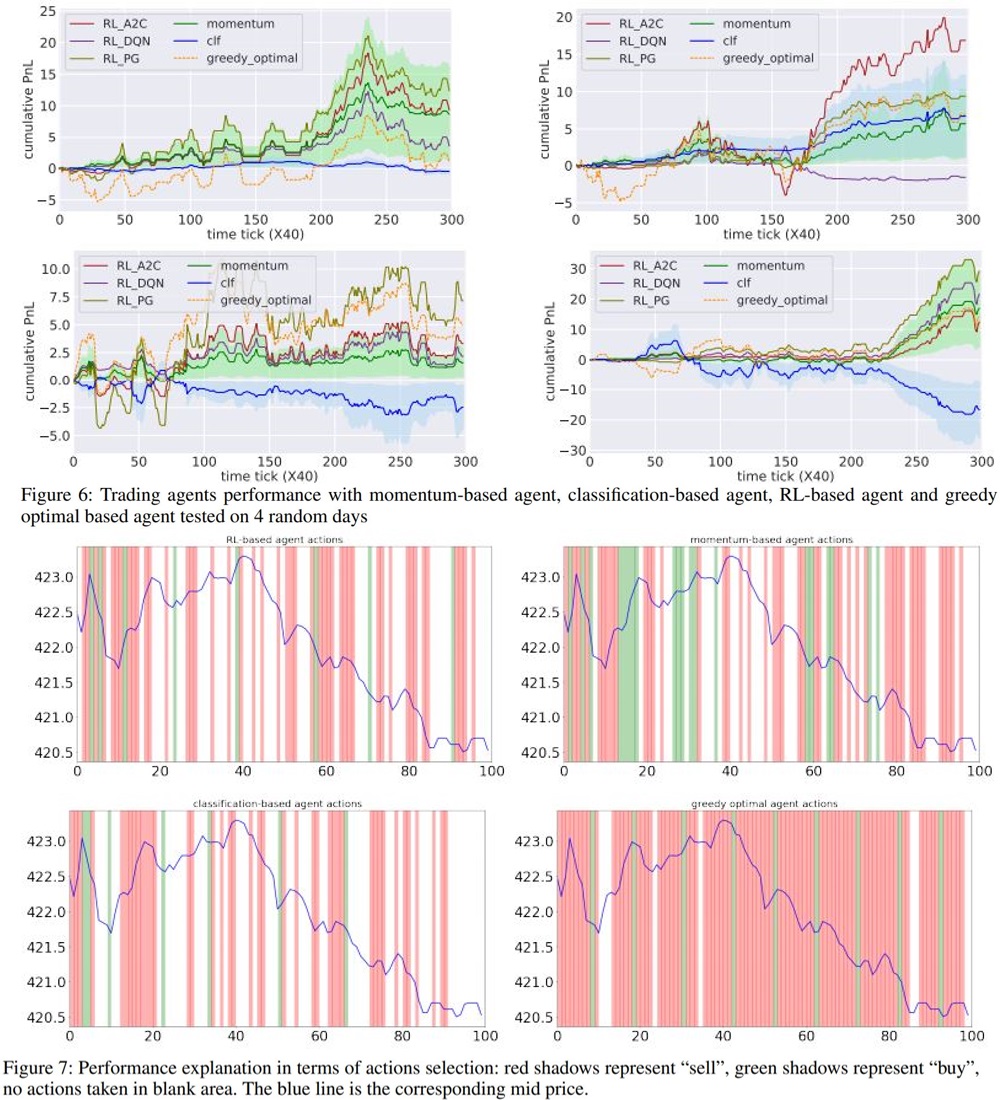
비교를 좀 해봤다고 한다.
- Momentum agent: 사고 팔고의 전환이 너무 잦다.
- RL agent: 국소 저점에서 사고 국소 고점에서 판다.
- Classifier agent: 사는것도 파는것도 거의 안한다.
- Greedy Optimal: 1 단계 후의 가격이 떨어질 때는 action을 취하지 않고, action을 취하는 빈도가 제일 잦다.
또한, 상승장, 하락장, 변동성장에서 각 agent의 성적을 비교해 봤는데, RL agent는 상승장과 하락장에서 특히 성적이 좋았다고 한다. 변동성장에서는 비교적 성적이 안좋았는데, 변동성장에 해당하는 데이터가 많이 없어서 그런 것 같다고 평가했다.
Agent의 성능 뿐 아니라, 이 논문에서 시도한 호가창의 모델링에 대해서도 코멘트를 한다. 랜덤하게 선택된 5일간의 데이터에 대해서 같은 RL agent가 실제 환경과 world model에서 각각 트레이딩을 진행했는데, 누적 성과가 비슷한 것을 볼 수 있었다. 상당히 흥미로웠는데, 호가창 자체를 하루단위로 모델링 하는 것에 어느정도 성과를 보였다는 것은 대단한 것 같다.
My Conclusion
갓 제이피! 너무너무 비슷한걸 구현해보고싶다.
Leave a comment