[Paper Review] VQ-WAV2VEC: Self-Supervised Learning of Discrete Speech Representations
wav2vec의 후속 연구입니다.
AIM: Discretisation + Wav2Vec
Wav2vec이 잘났다고 주장하던 사람들이 바로 새로운 것을 들고옴. discretisation을 기존 모델에 추가한 것인데, 왜 이것을 하려고 할까? 저자들은 wav2vec이 quantised output을 반환한다면 이 반환값으로 기존 NLP에서 쓰이는 모델의 인풋 으로 쓰일 수 있을 것이라고 한다. 확실히 대부분의 NLP 모델은 이산값을 인풋으로 받고 있기는 한데.. 잘 되는지 봅시다.
Overview
Wav2vec framework에서 discretisation을 더한 모델. 아래 그림을 보면 된다.
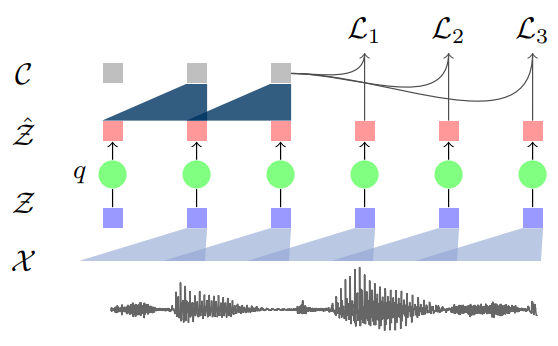
기존의 wav2vec은 \(\mathcal{X}\mapsto\mathcal{Z}\mapsto\mathcal{C}\)의 구조로 되어있었다. Vq-Wav2vec은 여기 중간에 \(\mathcal{Z}\mapsto\hat{\mathcal{Z}}\)을 추가한다. Latent Representation을 나타내는 \(\mathcal{Z}\)는 이전 몇 frame의 raw audio를 나타내는 저차원 표현이었는데, \(\hat{\mathcal{Z}}\) 라는 discrete 공간으로의 transformation을 한번 추가하면서 논문에서 추구하는 오디오 파일의 discrete representation을 이룰 수 있었다. 즉, 고정된 오디오 시그널의 representation인 것이다.
이산화를 이루기 위하여 논문은 Gumbel-Softmax approach와 online k-means clustering 방법을 사용한다. 여기서 나온 아웃풋을 버트와 같이 이미 널리 쓰이고 있는 NLP모델의 인풋으로 사용하는 예시도 보여주고 있다.
Background
Wav2vec과 BERT에 대한 이해가 필요하다. 논문은 링크에 걸어 두었는데 간략히 소개하면,
Wav2vec 은 self-supervised context-prediction task를 word2vec과 같은 loss를 최소화하는 방식으로 해결하면서 오디오 데이터의 representation을 학습하는 모델이다. Latent space를 학습하는 encoder network과 context space를 학습하는 context network(본 논문에서는 aggregation network라 칭함)으로 이루어져 있다. 자세한 부분은 Wav2vec을 다룬 블로그 포스트나 논문을 참고하면 된다.
BERT 는 NLP문제를 풀기 위한 pre-trained모델로, 양방향 트랜스포머 네트워크를 사용하여 텍스트 데이터의 representation을 학습한다. BERT는 크게 두가지 문제를 풀면서 학습이 진행되는데, 글에서 랜덤하게 가려진 단어를 맞춰야 하는 MLM (Masked Language Modelling)과 주어진 두 문장이 실제 글에서 순차적으로 등장한 문장들인지를 맞춰야 하는 NSP (Next Sentence Prediction)문제가 그것이다.
여기서 말하는 representation은 흔히들 알고 있는 임베딩이라고 생각하면 되고, 생소하다면 이 글을 읽으면 된다.
Model
모델 구조는 wav2vec과 거의 동일하다. 다만 \(\mathcal{X}\mapsto\mathcal{Z}\mapsto\mathcal{C}\)로 이어지는 공간 변환 중간에 discrete space를 하나 추가하여 아래와 같이 된다.
\[\mathcal{X}\mapsto\mathcal{Z}\mapsto\mathcal{\hat{Z}}\mapsto\mathcal{C}\]한번 더 정리하면, \(f: \mathcal{X}\mapsto\mathcal{Z}\)는 raw audio에서 feature extraction을 통한 latent space 학습을 하는 과정, quantization module이라고 불리는 \(q: \mathcal{Z}\mapsto\hat{\mathcal{Z}}\)은 discrete representation을 학습하는 과정, 마지막 \(g: \hat{\mathcal{Z}}\mapsto\mathcal{C}\)는 context를 뽑아내는 과정이다.
더 자세히 들어가자면, wav2vec에서는 약 30ms의 오디오가 \(f\)를 통해 \(z\)로 표현이 되었다. 각 \(z\)는 10ms의 stride를 가지고 있다. 이제는 그 \(z\)가 \(q\)를 통해서 이산 인덱스(discrete index) 로 표현이 되는 것이다. 각 인덱스는 \(z\)의 reconstruction인 \(\hat{z}\)에 매핑되어 있는 형태이다.
즉, \(q\)가 \(z\)를 받으면 \(z\)를 어떠한 하나의 인덱스로 변환을 하고, 따로 저장하고 있는 map에서 그 인덱스에 해당하는 새로운 representation(\(\hat{z}\))을 찾아 반환한다는 뜻이다.
그 map은 codebook이라고 불리는 \(V \times d\)차원의 행렬으로, \(V\)는 representation의 개수(\(\hat{z}\)의 개수), \(d\)는 각 \(\hat{z}\)의 차원을 의미한다. \(q\)가 \(z\)를 받으면, Gumbel-Softmax나 online k-means중 한가지 방법을 사용하여 \(z\)를 인덱스로 바꾸고, 그 인덱스에 해당하는 \(\hat{z}\)을 \(V\)개 중에서 찾아 반환하는 형태이다.
이 다음은 wav2vec과 동일하다. \(\hat{z}\)을 \(g\)에 넣어 \(c\)가 반환되면 그 \(c\)와 positive, negative sample들을 가지고 모델을 학습하는 것이다.
Quantization Module
Gumbel-Softmax와 online k-means에 대한 설명.
Gumbel-Softmax 는 categorical latent representation을 표현하기 위해 쓰이는 기법이며, 원핫 벡터를 계산하기 위한 argmax의 미분 가능한 approximation이다. 인풋 \(z\)가 들어오면 FC, ReLU, FC를 순차적으로 거친 후 \(V\)차원의 logit 벡터 l을 반환한다. Inference시에는 \(l\)의 원소 중 가장 큰 원소에 해당하는 인덱스를 사용하는 것이다. 학습시에는 \(j\)번째 원소의 확률은 아래와 같이 표현된다.
\[p_j=\frac{exp(l_j+v_j)/\tau}{\sum^{V}_{k=1}exp(l_k+v_k)/\tau}\]\(v = -log(-log(u))\), \(u~Uniform(0,1)\)이며, \(\tau\)는 Gumbel-Softmax에서 temperature라고도 불리는 하이퍼파라미터이지만, 파라미터로 놓고 학습을 통해서 정해지게 실험한 케이스도 있다고 한다. \(\tau>0\)일 때에 Gumbel-Softmax는 미분가능하며, backprop을 할 때 유용한 성질을 제공해준다. \(\tau\)에 대한 자세한 설명은 이 논문을 참고하면 되고, 간단한 설명은 아래와 같다. (해당 논문에서 발췌)
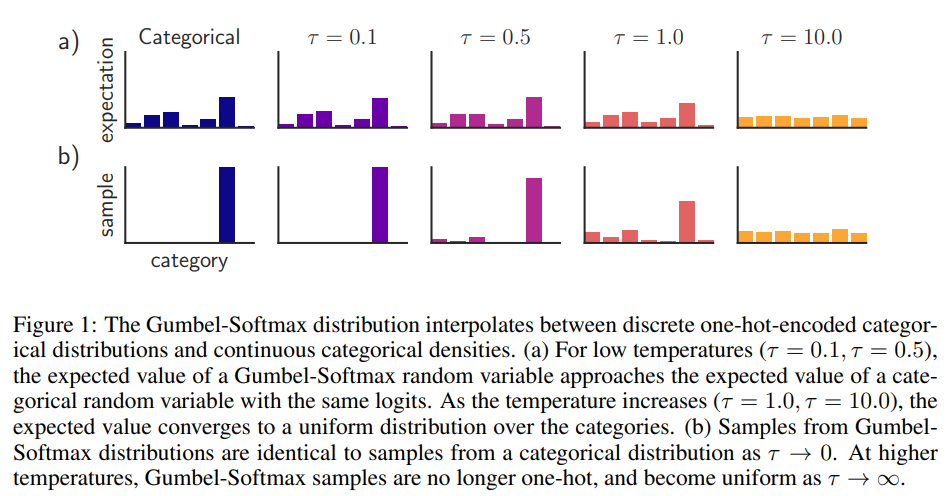
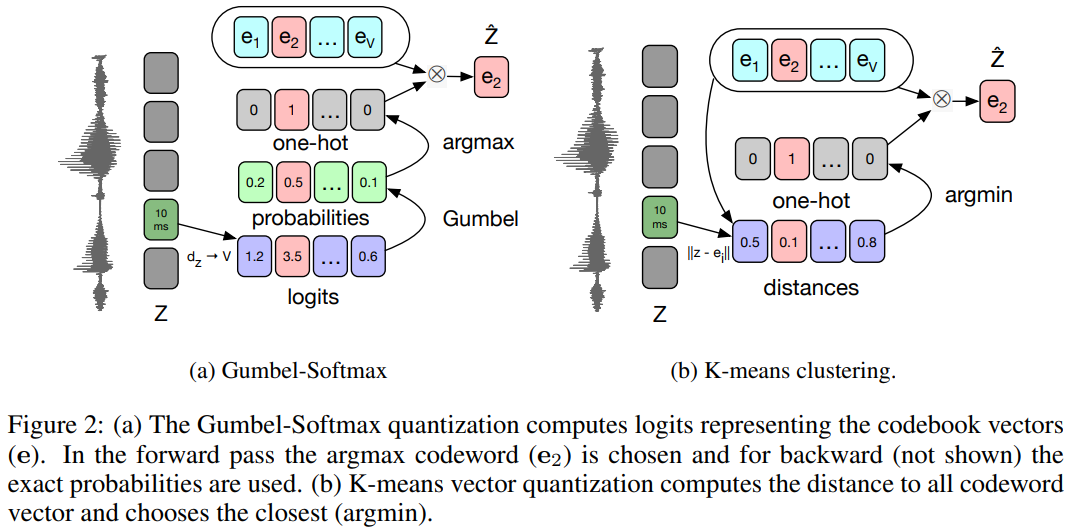
정리를 하면, forward pass에서는 \(i = argmax_j(p_j)\)인 것이고, backprop할 때는 Gumbel-Softmax를 그대로 미분하여 쓰면 된다.
Online k-means 는 또다른 인덱스 선택 방식을 미분가능하게 표현한 것이다. Codebook에서 \(d\)차원짜리 representation을 반환 할 때, 인풋 \(z\)와 유클리디안 거리가 가장 가까운 \(\hat{z}\)을 반환하는 방식이다. Online k-means와 연결 되어있는 encoder network의 gradient를 구하기 위해서 dL_wav2vec/dz_hat을 사용하는데, k-means를 사용하기 위해서는 loss가 아래와 같이 된다.
\[\mathcal{L}=\sum^{K}_{k=1}\mathcal{L}^{wav2vec}_k+\big( \lVert sg(z)-\hat{z} \lVert^2 + \gamma\lVert z-sg(\hat{z}) \lVert^2 \big)\]여기서 \(sg\)는 forward pass 에서는 입력을 그대로 반환하는 identity인데, gradient는 0을 반환하는 ‘stop gradient’ operator 이다. 위의 식에서 첫번째 항은 future prediction task를 위해 쓰이는 항으로 backprop할 때 codebook의 변화는 없다. 하지만, 두번째 항은 codebook의 벡터를 encoder output과 가까이 만들어주고, 세번째 항은 encoder output이 k-means의 centroid (codeword)와 가깝게 만들어 주는 역할을 하게 되는 것이다. 즉, \(sg(z)\)를 미분하면 0이기 때문에 두번째 항은 codebook을 바꿔주고, 세번째 항은 encoder network를 바꿔준다고 생각하면 된다.
그림 설명은 아래와 같다.
Implementation details
실제로 위에 있는 것처럼 naive하게 구현을 하면 mode collapsing이 생기게 된다. 다시 말하면, \(V\)개의 임베딩 중 실제로 쓰이는 것은 몇개가 안된다는 뜻한다. 보통은 codebook의 초기화를 바꾼다거나 regularisation을 추가로 하는 등의 방법이 있는데, 이 논문에서는 \(z\)를 일대일로 quantise하지 않고, \(z\)를 partition하여 각 partition을 독립적으로 일대일로 quantize하는 방법을 사용하고 있다.
먼저 \(z\)벡터(\(d\)차원)를 여러개의 group으로 나눈다(partitioning). 총 G개의 그룹이 있다고 한다면, \(z\)는 \(G \times (frac{d}{G})\)차원의 행렬이 되는 것이다. 그렇다면 \(z\)를 나타내기 위해서는 인덱스가 \(G\)개 필요하게 된다. 또 한가지 생각해야 하는 부분은 해당 partition이 여러 \(z\)에 걸쳐서 공유되게 세팅할 수도 있다는 것이다. 이 경우에는 codebook의 차원은 \(V \times \frac{d}{G}\)가 되는 것이다. 만약 공유를 안한다면 \(V \times G \times \frac{d}{G}\)의 차원을 가지고 있었을 겁니다. Partition을 공유한다면 \(\frac{d}{G}\)차원의 벡터를 조합하여 \(z\)를 만드는 것이고, 공유하지 않는다면 \(z\) 1개에 \(G\)개의 group이 각각 필요하게 되는 것이기 때문이다. 실제로는 공유하게 만들어 놓은 것이 성능이 좋았다고 한다.
Experiment
Wav2vec때와 비슷하게 downstream model을 사용하였는데, 한가지 다른점이 있다면 바로 BERT의 사용이다. Vq-wav2vec은 discrete output을 내놓기 때문에 BERT와 같이 discrete input을 받아야 하는 모델과 같이 쓰이기 편하다.
그래서, vq-wav2vec의 학습이 끝난 후에 그 아웃풋을 BERT에 넣어서 BERT module을 학습시켰는데, 기존 BERT의 학습과 다른 점 두가지를 적용했다. 한가지는 NSP를 사용하지않고 MLM만 사용했다는 점이고, 두번째는 MLM에서 연속적인 토큰을 mask했다는 점이다. vq-wav2vec의 아웃풋이 약 10ms의 오디오를 임베딩 한 토큰이기 때문에 mask를 discontinuous하게 했을 경우 너무 쉬운 문제가 되어버려서, 랜덤하게 5%의 확률로 시작 토큰을 정해서 약 10개(100ms 정도)의 토큰에 mask를 씌워 MLM을 학습한 것이다.
Data
vq-wav2vec과 BERT모두 960시간의 Librispeech데이터를 사용하여 학습하였고, 학습이 끝난 후 vq-wav2vec은 총 345M개의 토큰을 반환하는 모델이 되었다. 다른 실험 세팅에서는 100시간이 39.9M개의 토큰으로 discretized되는 것도 있었다. 역시 wav2vec과 마찬가지고 TIMIT과 WSJ에 대해서 evaluation을 진행하였다.
Training Details
- Vq-wav2vec Fairseq를 사용해 구현하였으며 총 34x10^6개의 파라미터를 가지는 모델이다. Encoder network는 512채널을 가지는 CNN 레이어 8층을 쌓았고, 커널 사이즈는 (10,8,4,4,4,1,1,1), 스트라이드는 (5,4,2,2,2,1,1,1)이어서 총 스트라이드는 160이 된다. 각 레이어는 CNN 후에 droupout과 instance normalization, ReLU가 적용되었다. Context network (aggregation network)는 512채널의 12층 레이어로, 스트라이드 1, 커널 사이즈는 2부터 시작하여 다음 층으로 갈때마다 1개씩 늘어가는 구조이다. Encoder network와 다른 detail은 똑같지만, context network에는 block 사이에 skip connection을 사용하였다. Wav2vec과 비슷하게, future step을 나타내는 K는 8로, negative sample의 수는 10개로 지정하였으며, learning rate은 초반 500 step까지는 늘다가 그 후부터 cosine schedule에 따라 10^-6까지 감소하게 만들었다. 배치 사이즈는 10개이며, 150k frame에 맞게 인풋 데이터를 잘라 넣었다. 모든 모델은 GPU 8개로 학습되었다.
- Gumbel-Softmax Models 그룹의 개수는 2개(G=2), 각 그룹당 latent representation은 320개(V=320)으로, Gumbel-Softmax의 첫 FC가 반환하는 벡터는 총 640차원(320*2)이다. 각 그룹마다 한개의 원핫 벡터를 반환하고, 첫 70%의 스텝에서 temperature tau는 2부터 0.5까지 감소시켰고 그 후에는 0.5로 고정시켰다. 960시간의 데이터에 학습이 완료되고 난 후에는 13.5k의 codewords로 이루어진 codebook이 만들어졌다. (\(V^G\)=102k개가 총 가능한 codeword 수)
- k-means Models 위와 똑같이 G=2, V=320으로 두었으며, full Librispeech에서 학습했을 시 23k의 unique codewords가 나왔다. gamma는 0.25로 고정시켰다. (van den Oord, 2017을 참고)
- BERT
- Bert base 768차원 네트워크가 12개가 있고, 내부 FFN은 3072차원이고 attention head는 12개를 가져갔다. 각 token은 10ms의 오디오 데이터를 임베딩한다.
- BERT small 작은 모델은 512차원 네트워크를 사용하였고, FFN 크기는 2048, attention head는 8개를 사용하였다.
- Acoustic Model Wav2vec과 마찬가지로 downstream task를 위한 모델로, WSJ에서 학습시킨 4-gram KenLM모델과 character-based convolutional language model을 사용했다.
Results
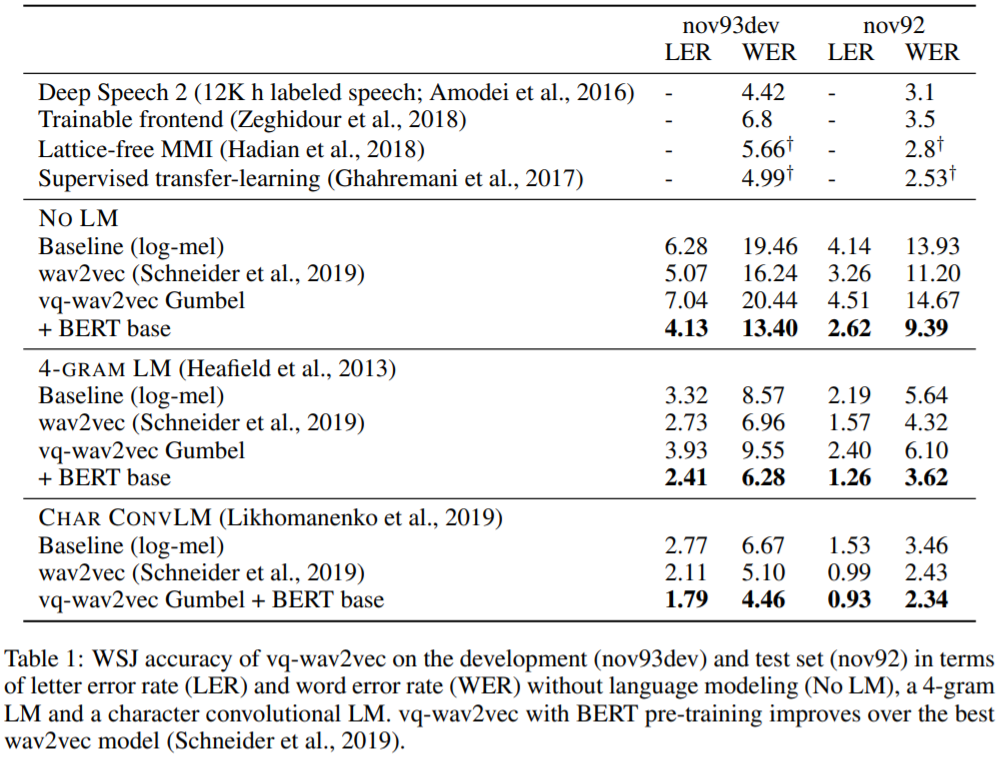
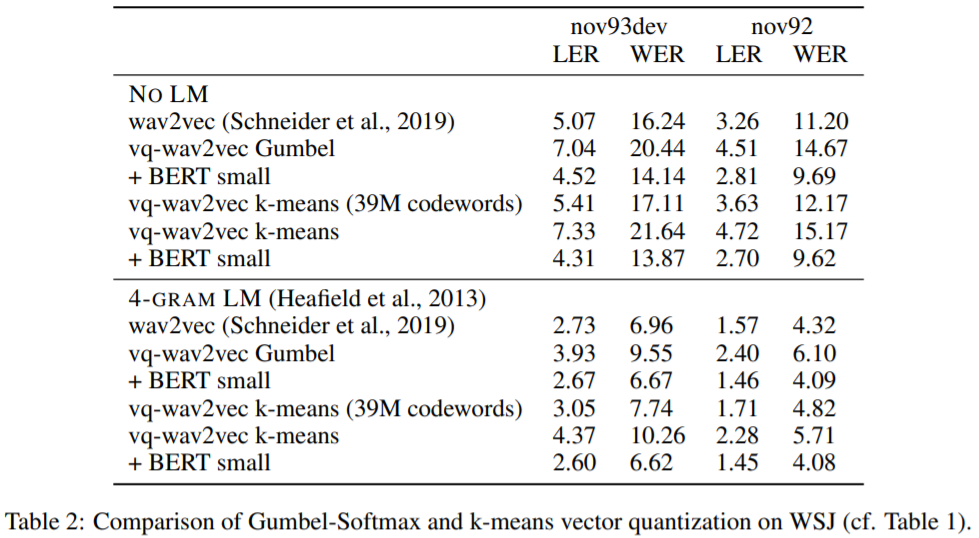
BERT와 함께 쓸 것이 아니면 굳이 vq-wav2vec을 wav2vec 대신 쓸 필요는 없다. 논문에서 나온 결과도 BERT의 힘을 빌렸을 때 vq-wav2vec이 더 좋은 결과를 냈다고 한다. Gumbel과 k-means모두 wav2vec과 vanilla로 맞붙었을 때는 졌다.
My Conclusion
애초에 quantize를 할때 정보손실이 많이 일어나는 것 같습니다. 그 정보손실을 감수하면서까지 quantize를 하는 이유는 BERT와 같이 다른 NLP모델과의 hybrid를 위해서 인 것 같은데요, 그럴 일이 없고 그냥 audio embedding이 필요한 상황엔 wav2vec을 쓰는게 더 나을 수도 있겠습니다.
Leave a comment