[Paper Review] Efficient Exploration via State Marginal Matching
Arxiv 링크
새해 복 많이 받으세요. 역시 새해는 강화학습과 함께.
Levine, Xing의 팀이 낸 논문. 강화학습에서 풀고자하는 큰 문제 중 하나인 ‘탐색’을 체계적으로 수행하기 위한 독특한 문제로 정의함. 상태 사전분포에 최대한 가깝게 탐색할 수 있는 법을 학습하는 ‘State Marginal Matching’ (이하 SMM)을 제안함.
Introduction
강화학습에서 흔히 일어나는 딜레마는 exploration-exploitation trade off이다. 지금까지 얻은 정보를 바탕으로 최적이라고 생각하는 행동을 계속 함으로써 보상을 늘려나가는 결정이 exploitation (착취)이고, 혹시라도 더 높은 보상을 받을 수 있는 상황이 있을 수도 있기 때문에 새로운 정보를 수집하려고 다양한 행동을 취하고 다양한 상태에 도달하려고 하는 결정이 exploration (탐색)이다. 둘 사이에는 적당한 균형이 중요한데, 탐색의 경우는 수행하기 비싼 경우가 많기 때문에 최대한 효율적으로, 적은 시도를 통해 최대한의 정보를 얻을 수 있는 방법이 연구되고 있다. 이 논문도 해당 문제를 해결하려는 시도이다.
가장 기본적인 탐색 방법은 이미 널리 알려진 \(\epsilon\)-greedy방법일 것이다. 적은 \(\epsilon\)의 확률로 랜덤한 행동을 취하고 나머지 \(1-\epsilon\)의 확률로는 현재 최적이라고 생각하는 행동을 취하는 방법이다. 이외에도 더 체계적인 탐색 방법이 제안되었다. Intrinsic motivation방법(논문 링크)은 외부 보상 신호가 없을 때 비지도 방식으로 정책을 학습하는 방법인데, 에이전트에 내재된 보상을 생성하고 그것을 달성하기 위한 행동을 결정하면서 나중에 실제 보상 신호가 들어왔을 때 효율적으로 수행할 수 있게 한다.
이 논문에서 주장하는 기존 방법의 문제점은 크게 두 가지이다. 먼저, ‘좋은 탐색’이 무엇인지 제대로 수치화할 수 없다는 것이다. 잘 정의된 최적화 문제를 해결하면서 탐색을 하는 것이 아니기 때문에 탐색하는 행동을 제대로 이해할 수 없다는 것이 문제이다. 또한, 탐색의 질을 평가할 수 없기 때문에 알고리즘간 비교가 어려운 것이 이 분야의 발전을 저해한다고 주장한다. 두번째는 기존 탐색 방법은 한 가지 과업을 수행하는 데만 도움을 주기 때문에 다양한 과업으로 일반화가 어렵다는 점이다.
이 논문에서 제안하는 SMM은 상태 사전 확률분포가 주어졌을 때 에이전트가 방문한 상태의 분포가 그 사전분포와 최대한 가깝게 하는 정책을 학습하는 방법이다. 체계적인 학습을 가능하게 할뿐 아니라 미래에 수행해야 하는 task와 관련하여 상태에 대한 사전 지식을 주입할 수 있다는 장점이 있다. 예를 들어 에이전트가 꼭 따라야 할 제약조건을 반영한다거나, 상대적으로 중요한 task를 수행하기 위해 더 많은 경험이 필요한 상태에 가중치를 주는 방식으로 사전 지식을 활용해 사전 확률분포를 만들 수 있다. 에이전트는 주어진 사전 확률분포와 최대한 동일하게 자신이 방문할 상태의 빈도를 맞추는 정책을 학습해야 한다. 만약 사전 지식을 넣지 않는다면 상태의 사전분포는 균등분포가 되어서 SMM의 목표는 주변 상태 엔트로피 (Marginal State Entropy) \(\mathcal{H}[s]\)를 최대화하는 문제가 되며, 에이전트가 모든 상태를 방문하도록 유도한다. 이 탐색 알고리즘을 학습하는 데는 외부의 보상 함수가 필요하지 않다. 어떠한 task가 주어지냐에 상관 없는 탐색 알고리즘인 것이다.
즉, 제대로 정의된 최적화 문제를 해결함으로써 ‘탐색 정책’이라는 함수를 학습하는 방법을 제안한다. 이를 통해 탐색을 평가하고, 분산시키고, 이해할 수 있다.
State Marginal Matching
이 논문에서 제안하는 SMM을 이해하기 전에 prediction error기반 탐색 기법과 그 문제점을 살펴보자. Prediction error기반 탐색 기법은 특정 예측 모델의 성능을 기반으로 하나의 전이로부터 최대 정보를 얻는 정책을 학습하는 방법이다. 예를 들어서 다음 상태를 얼마나 예측할 수 있었느냐를 기반으로 정보량을 측정할 수도 있고 (다음 상태를 예측하기 힘들었으면 얻은 정보량이 많은 것으로 본다), 이전 상태와 다음 상태가 주어졌을 때 어떠한 행동을 취했을지를 얼마나 잘 예측했냐를 기반으로 정보량을 측정할 수도 있다. 하지만 이 방법은 하나의 탐색 정책으로 수렴하지 않는다.
예를 들어서, Pathak et al.의 ICM에서 정의한 목적함수를 따라가면 모델이 수렴했을 때 모든 상태에 대해서 에러가 0이 되어서 탐색을 계속 하는 것에 대한 추가 보상이 없어지게 된다. 즉, 수렴했을 때 탐색에 관련된 목적함수 항은 정책에 아무런 영향을 끼치지 못한다. SMM은 목적함수를 최적화하는 방식으로 얻어진 탐색 정책이 존재해서 그 탐색 정책을 따라서 탐색을 효율적으로 수행할 수 있음을 보였다.
SMM은 상태 주변 분포를 가장 잘 재구성할 수 있는 정책을 학습하는 것을 목표로 한다. 구해진 정책을 따라가면 상태의 사전분포와 최대한 비슷한 확률로 상태를 방문하는 것이다. 먼저 상태 주변 분포를 정의해보자.
행동 \(a\)를 취할 수 있는 정책 \(\pi_\theta\in\Pi\triangleq\{\pi_\theta\mid\theta\in\Theta\}\)가 있고, 이 정책이 정의되는 전이분포 \(p(s_{t+1}\mid s_t,a_t)\)와 초기 상태 분포 \(p_0(s)\)를 가지고 있는 길이 \(T\)의 MDP(마르코프 결정 과정)가 있다고 하자. 먼저, 앞에서 정의된 요소들로 상태를 생성할 수 있는 분포를 얻을 수 있음을 생각하자. 초기 분포에서 초기 상태를 뽑고 정책에서 행동을 뽑아 전이분포에 넣으면 다음 상태를 얻을 수 있기 때문이다.
State Marginal Distribution(상태 주변 분포) \(\rho_\pi(s)\)를 다음과 같이 정의한다. 해당 정책이 상태 \(s\)를 방문할 확률이다.
\[\rho_\pi(s)\triangleq\mathbb{E}_{\substack{s_1\sim p_0(S),\\a_t\sim\pi_\theta(A\mid s_t)\\ s_{t+1}\sim p(S\mid s_t,a_t)}}\Bigg[\frac{1}{T}\sum\limits^T_{t=1}\mathbb{I(s_t=s)}\Bigg]\]상태에 대한 사전분포 \(p^*(s)\)가 주어졌을 때, SMM의 목적은 \(p^*(s)\)와 가장 가까운 \(\rho_\pi(s)\)를 만드는 \(\pi\)를 구하는 것이다. 가까움의 정도는 KL발산으로 측정한다. 목적함수를 아래와 같이 적을 수 있다.
\[\underset{\pi\in\Pi}{\text{min}}\,D_{\text{KL}}(\rho_\pi(s)\lVert p^*(s))\triangleq \underset{\pi\in\Pi}{\text{max}}\,\mathbb{E}_{\rho_\pi(s)}\log p^*(s)+\mathcal{H}_\pi[s]\]마지막 표현을 최대화하는 것은 pseudo-reward인 \(r(s)\triangleq\log p^*(s)-\log\rho_\pi(s)\)를 최대화하는 것과 같다고 생각할 수 있다. 지금 정책 \(\pi\)를 따르고 있기 때문에 기댓값을 근사할 수 있기 때문이다. 이 보상함수의 의미는 사전분포에 비해서 많이 방문한 상태에 도달했을 때는 패널티를 주고, 사전분포에 비해 적게 방문한 상태에 도달했을 때는 보상을 주는 것이다. 하지만 이 보상함수는 강화학습의 목표라고 하기 어려운데, 정책이 바뀌면 보상함수도 바뀌기 때문이다. 상태 엔트로피인 두 번째 항을 regularizer라고 생각하면, 이 regularizer가 없을 때는 정책이 \(p^*(s)\)의 최빈값(mode)에 수렴하게 된다. 두번째 항이 있음으로써 적절한 탐색을 하는 것이며, 행동에 대한 조건부 항이 없기 때문에 행동에 대한 탐색이 아닌 상태에 대한 탐색이 이루어진다. 진정한 의미의 탐색이라고 할 수 있다.
여기까지가 바닐라 SMM이라고 한다면, target distribution이 멀티모달일 경우에는 Mixture Model 구조를 활용하여 다른 버전을 제안할 수 있다. 멀티모달 \(p^*(s)\)일 경우에는 각 모드에 해당하는 분포를 따로 학습 한 후에 다시 합치는 방안이 학습하기 더 쉬울 것이다. 이를 위해 잠재변수 \(z\)를 사용한다. \(\rho_{\pi_z}(s)\)를 잠재변수 \(z\)가 주어졌을 때 정책의 상태 분포라고 한다면, 사전분포 \(p(z)\)가 주어졌을 때 각 \(z\)에 해당하는 정책 \(\pi_z\)의 혼합 상태 주변 분포는 아래와 같이 나타낼 수 있다.
\[\rho_{\pi}(s)=\int_{\mathcal{Z}}\rho_{\pi_z}(s)p(z)dz=\mathbb{E}_{z\sim p(z)}[\rho_{\pi_z}(s)]\]베이즈 정리를 사용하고 위에서 보여준 KL발산 최소화 식을 다시 써본다면 목적함수는 다음과 같이 바뀌게 된다.
\[\underset{\substack{\pi_z\\z\in\mathcal{Z}}}{\text{max}}\,\mathbb{E}_{\substack{p(z),\\\rho_{\pi_z}(s)}}[r_z(s)]\\ r_z(s)\triangleq\log p^*(s)-\log\rho_{\pi_z}(s)+\log p(z\mid s)-\log p(z)\]각 항이 나타내는 의미는 다음과 같다. 에이전트가 target distribution에 맞는 상태를 방문해야하고, 에이전트가 지금까지 방문하지 않은 상태를 방문해야 하며, 다른 \(z\)를 따르는 에이전트와 충분히 구별가능해야하고, \(z\)공간에서도 충분히 탐색이 이루어져야 한다는 것을 나타낸다. 이전 연구에서도 상호정보량(Mutual Information)을 사용하여 이와 비슷한 방식을 취했는데, 제일 다른 점은 바로 두번째 항인 \(-\log\rho_{\pi_z}(s)\)를 포함시킨 것이다. 완전히 새로운 상태를 방문했을 때 부여되는 보상인데, 위에서 언급한 상태에 대한 탐색과도 연관 되어있는 이 항 때문에 과거 기법에 비해서 월등한 성능을 자랑할 수 있었다고 주장한다.
A Practical Algorithm
이제 위에서 제안한 최적화 문제를 어떻게 해결할 것인가를 살펴본다. 핵심 내용은 게임이론을 사용한 접근법을 취했다는 것이다. 정책함수가 바뀜에 따라 보상함수도 바뀌기 때문에 순환적인 의존성이 있어서 게임이론적 접근법이 충분히 말이 된다.
상태 주변 분포 \(\rho_\pi(s)\)를 근사하는 모수 모델 \(q_\psi(s)\in Q\triangleq\{q_\psi\mid\psi\in\Psi\}\)를 만들어서 각 \(\pi\in\Pi\)마다 \(D_{\text{KL}}(\rho_\pi(s)\lVert q(s))=0\)를 만족시키는 \(q\in Q\)가 있다고 한다면 아래의 등식이 성립한다.
\[\underset{\pi}{\text{max}}\mathbb{E}_{\rho_\pi(s)}[\log p^*(s)-\log\rho_\pi(s)]\\=\underset{\pi}{\text{max}}\,\underset{q}{\text{min}}\mathbb{E}_{\rho_\pi(s)}[\log p^*(s)-\log q(s)]\]위의 식을 보이기 위해 아래 식을 따라가보자.
\[\mathbb{E}_{\rho_\pi(s)}[\log p^*(s)-\log q(s)]=\mathbb{E}_{\rho_\pi(s)}[\log p^*(s)-\log q(s)-\log\rho_\pi(s)+\log\rho_\pi(s)]\\=\mathbb{E}_{\rho_\pi(s)}[\log p^*(s)-\log \rho_\pi(s)]+\mathbb{E}_{\rho_\pi(s)}[\log\rho_\pi(s)-\log q(s)]\\=\mathbb{E}_{\rho_\pi(s)}[\log p^*(s)-\log \rho_\pi(s)]+D_{\text{KL}}(\rho_\pi(s)\lVert q(s))\]이제 \(\text{maxmin}\)목적함수를 써보자.
\[\underset{\pi}{\text{max}}\,\underset{q}{\text{min}}\mathbb{E}_{\rho_\pi(s)}[\log p^*(s)-\log q(s)]\\=\underset{\pi}{\text{max}}\Big(\mathbb{E}_{\rho_\pi(s)}[\log p^*(s)-\log \rho_\pi(s)]+\underset{q}{\text{min}}\,D_{\text{KL}}(\rho_\pi(s)\lVert q(s))\Big)\]첫번째 항은 \(q\)가 없기 때문에 \(\text{min}\)이 두번째 항에만 취해졌다. 또한, 위의 가정을 사용하면 \(\underset{q}{\text{min}}\,D_{\text{KL}}(\rho_\pi(s)\lVert q(s))=0\)을 만족하는 \(q\)를 대입할 수 있다. 즉,
\[=\underset{\pi}{\text{max}}\Big(\mathbb{E}_{\rho_\pi(s)}[\log p^*(s)-\log \rho_\pi(s)]\Big)\]이 됨을 알 수 있다. 이 최대-최소 문제를 푸는 것은 stationary 내쉬 균형을 찾는 것과 같은 문제이다. 여기에서 두 player는 \(\pi\)를 찾으려는 정책 player와 \(q\)를 찾으려고는 분포 player가 된다. 이 문제를 해결하는 데는 fictitious play의 개념을 도입하여 내쉬 균형을 유한시간안에 찾는 알고리즘을 사용한다. 각 iteration마다 한 player는 상대방의 전략의 historical average를 보고 (상대의 전략을 historical average로 고정한다는 뜻이다) 그에 대응하는 최고의 수를 두는 것이다. 분포와 정책의 historical average를 \(\bar\rho_m(s)\triangleq\frac{1}{m}\sum^m_{i=1}\rho_{\pi_i}(s)\)이고 \(\bar q_m(s)\triangleq\frac{1}{m}\sum^m_{i=1}q_i(s)\)라고 정의한다면 아래와 같은 fictitious play방식으로 최적화를 진행한다.
\[q_{m+1}\leftarrow\text{arg}\underset{q}{\text{max}}\mathbb{E}_{s\sim\bar\rho_m(s)}[\log q(s)]\\ \pi_{m+1}\leftarrow\text{arg}\underset{q}{\text{max}}\mathbb{E}_{s\sim\rho_\pi(s)}[\log p^*(s)-\log \bar q_m(s)]\]정책 \(\pi_1,\cdots,\pi_m\)으로 이루어진 Historical Average Policy \(\bar\pi(a\mid s)\)는 각 반복 단계에 해당하는 정책 중 랜덤으로 하나를 샘플한 것이다. 각 에피소드가 시작할 때 \(\pi_i\sim\text{Unif}[{\pi_1,\cdots\pi_m}]\)에 따라서 정책을 하나 샘플링 하고 그 정책을 에피소드가 끝날 때까지 따라간다.
이 방법을 정리한 알고리즘은 다음과 같다.

Fictitious Play를 활용한 최적화 방법을 Mixture Model로 확장시킬 수 있다. Mixture Model에는 잠재변수 \(z\)가 개입하여 상태 분포와 정책이 각 \(z\)마다 하나씩 존재한다는 것을 떠올리자. 먼저 \(q_z^{(m)}(s)\)를 사용하여 각 정책 \(\pi_z\)의 상태 주변 분포를 근사한다. 그 다음 판별자 \(d^{(m)}(z\mid s)\)를 학습한다. 이 판별자는 상태 \(s\)에 방문할 정책 \(\pi_z\)를 판별하는 역할을 맡는다. 어떠한 상태를 방문했느냐를 보고 어떠한 잠재변수를 사용하고 있는지 판단할 수 있어야 한다는 의미이다. 마지막으로 강화학습을 사용하여 앞서 정의한 Mixture Model 문제의 목적함수 \(r_z(s)\)를 최대화하는 정책 \(\pi_z\)을 각각 업데이트한다.
여기서 눈여겨봐야할 것은 판별함수 \(d(z\mid s)\)인데, 실제 분포함수의 하한을 정해준다는 것을 Jensen’s Inequality를 통해서 알 수 있다.
\[\mathbb{E}_{\substack{s\sim\rho_{\pi_z(s)}\\z\sim p(z)}}[\log d(z\mid s)]\leq\mathbb{E}_{\substack{s\sim\rho_{\pi_z(s)}\\z\sim p(z)}}[\log p(z\mid s)]\]Agakov 2004에서 발췌한 설명이다.
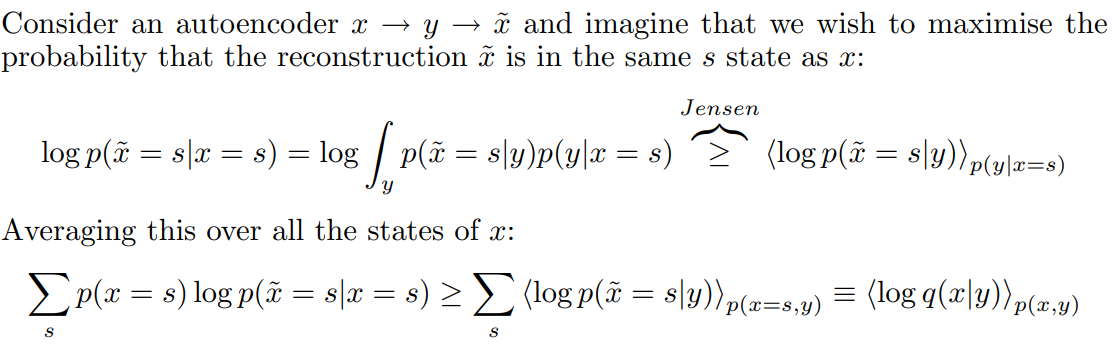
완성된 알고리즘은 아래와 같다. \(z\)를 1부터 \(n\)까지로 정한 것을 주의하자.

Prediction-Error Exploration is Approximate State Marginal Matching
이 부분에서는 기존 방법 중 prediction error기반 알고리즘이 SMM과 어떠한 관계가 있는지, 왜 다른 알고리즘보다 SMM이 우수한 성적을 냈는지 비교를 할 것이다. 정리하자면 기존 방법들을 시간에 따라서 평균내본다면 SMM과 거의 비슷한 목적함수를 최적화하지만, 목적함수에서 상태 분포에 대한 regularization이 없다는 점과 최적화할 때 게임이론에 기반한 historical average기법을 사용하지 않는다는 점이 가장 큰 차이점이다.
Objectives
먼저 기존 방법과 목적함수의 차이를 보자. 만약 SMM의 분포 모델이 VAE이고 \(p^*(s)\)이 균등분포라면 SMM의 목적함수는 prediction error방법들에서 사용하는 목적함수와 비슷해진다.
\[\underset{\pi}{\text{max}}\,\underset{\psi}{\text{min}}\mathbb{E}_{\rho_\pi(s)}[\lVert f_\psi(s_t)-s_t\rVert^2_2]+R_\pi(\psi)\]\(f_\psi\)는 오토인코더고 \(R_\pi(\psi)\)는 데이터 분포 \(\rho_\pi(s)\)에 대한 VAE의 KL 페널티이다. (\(\rho_\pi(s)\)와 VAE 사이의 KL발산) Prediction error 방법 RND에서 사용하는 목적함수는 다음과 같다.
\[\underset{\pi}{\text{max}}\,\underset{\psi}{\text{min}}\mathbb{E}_{\rho_\pi(s)}[\lVert f_\psi(s_t)-e(s_t)\rVert^2_2]\]\(e(\cdot)\)은 랜덤하게 초기화된 뉴럴넷 인코더이다. Forward model에 대한 predictive error를 준 모델의 경우에는 다음과 같다. 다음 상태를 예측하는 성능에 보너스를 준다.
\[\underset{\pi}{\text{max}}\,\underset{\psi}{\text{min}}\mathbb{E}_{\rho_\pi(s)}[\lVert f_\psi(s_t,a_t)-s_{t+1}\rVert^2_2]\]Inverse Model에서 유도된 탐색 알고리즘의 목적함수는 아래와 같다. 지금과 다음 상태를 가지고 택한 행동을 예측하는 것에 보너스를 주는 것이다.
\[\underset{\pi}{\text{max}}\,\underset{\psi}{\text{min}}\mathbb{E}_{\rho_\pi(s)}[\lVert f_\psi(s_t,s_{t+1})-a_t\rVert^2_2]\]결국 \(R(\psi)\)의 존재가 제일 큰 차이점을 만든다고 볼 수 있다. SMM이 수렴한 이후에도 계속해서 탐색을 하는 이유이다.
Optimization
Prediction error모델과 SMM의 큰 차이점 중 하나는 \(\text{max}\,\text{min}\)목적함수를 어떻게 최적화하냐에 있다. Prediction error모델의 경우에는 모델과 정책에 대해서 번갈아가면서 최적을 찾았다. Greedy한 방법이다. 하지만 가위바위보의 경우에서도 볼 수 있듯 greedy하게 최적화를 진행하면 수렴하지 않을 수도 있고, 이 논문에서 실제로 진행한 실험에서도 수렴하지 않는 모습을 볼 수 있었다.
반대로 SMM은 historical average를 사용한다. 정책의 historical average를 보고 모델을 업데이트 하고, 모델의 historical average를 보고 정책을 업데이트 하는 것이다. 이런 방식의 fictitious play는 수렴하는 것이 증명되어있다.
Prediction error방법은 수렴하는 것이 증명되어있지는 않지만 복잡한 task를 나름 잘 수행하는 것처럼 보이는데, 잘 살펴보면 목적함수를 학습하는 과정에서 탐색이 이루어져 결국 모든 상태를 방문하게 된다. 즉, prediction error방법에서 학습하는 중에 만들어지는 정책의 historical average를 보면 상당히 탐색을 잘 하는 정책이 되는 것이다. Prediction error방법에서 만들어진 replay buffer는 다양한 경험에 대한 정보를 담고 있는 것으로 생각할 수 있다. 결론적으로 prediction error방법에 fictitious play방식의 최적화를 이용한 historical average를 사용하면 탐색 성능의 향상을 볼 수 있다.
Others
Prediction error방법 이외에도 탐색 알고리즘을 찾는 시도가 있어 소개한다. 먼저, meta-RL방식으로 접근하는 방식이 있는데, SMM과의 차이점은 downstream task를 염두해두었냐에 대한 차이이다. Meta-RL은 downstream task의 보상함수 분포를 사용하여 어떻게 탐색하면 downstream task를 잘 수행할까에 초점을 맞췄다면 SMM은 downstream task가 주어지기 전에 탐색 정책을 학습할 수 있다.
다른 방식에는 정책 엔트로피를 높이는 방식이 있다. MaxEnt RL이라고 불리는데, SMM과의 차이점은 상태가 아니라 행동에 초점을 둔다는 것이다. 다양한 행동을 취하면 탐색을 한다고 생각하는 것인데, 어떻게 보면 맞는 말이지만 탐색이 진정으로 원하는 것은 다양한 상태를 방문하는 것이기 때문에 완벽히 목적이 일치한다고 보긴 힘들다. Levine의 2018년 리뷰 논문에도 잘 정리되어 있듯, MaxEnt RL은 강화학습 trajectory의 likelihood를 exponential reward로 정의하였을 때 그래프 모델에서 추론을 진행하는 것과 같은 것이다. Trajectory의 분포가 결국은 상태의 분포를 도출해내긴 하지만 trajectory에 대해서 적분한다는 것이 쉽지 않아서 intractable 문제가 되어버린다는 단점이 있다.
또한 Inverse RL이나 Imitation learning 등에서 사용된, 정책과 보상함수를 번갈아서 최적화하는 adversarial 기술이 적용되었다.
My Conclusion
드디어 강화학습에도 프리트레인 모델의 시대가 열린 것인가?! Off-policy 방식에서 behaviour policy로 사용할 수도 있고 활용 방안은 정말 많을 것 같다. 근데 구현은 언제?
Leave a comment