[Paper Review] Autoencoder Asset Pricing Models
제발 틀린거 있으면 피드백 주세요. 제발요.
논문 링크(SSRN)
Chicago Booth랑 내가 좋아하는 AQR에서 쓰고있는 논문. 계속 투자에 오토인코더를 어떤 식으로 활용하면 좋을지 생각하면서 논문을 찾고 있다가 발견했는데, 아마 작년에 읽은 논문 중 최고가 아니었을까 싶다. 라고 하기엔 작년에 읽은 논문이 몇 편 없다. 개 고양이 가리는 논문 포함해도 몇 편 없다.
일단 이 논문은 비슷한 사람들이 직전에 쓴 Characteristics are Covariances(KPS, 2019) 논문의 연구를 그대로 이어서 하고 있음. KPS에서는 자산가격결정을 위해 각 팩터의 loading을 동적으로, 하지만 선형적으로 주었다면 이번 논문에서는 이 부분에 오토인코더를 써서 비선형 요소를 넣어보자는 취지로 이해했는데.. 시작합시다.
Introduction
Chicago Booth 사람들인 만큼 assset return 에 factor anomaly를 도전하는 방향으로 논문을 진행한다. 선행연구인 KPS에서는 latent factor를 찾고 그 factor loading을 동적으로 바꿔줌으로서 risk factor가 anomalous return으로 인식되었던 부분을 거의 전부 설명할 수 있었다고 주장했다. Anomalous return이라고 취급받던 수익률 패턴은 결국 risk factor에 얼마나 동적으로 노출되고 있는가의 proxy에 지나지 않는다는 것이다. 수식으로 표현하자면,
\(r_{i,t} = \beta(z_{i,t-1})'f_t + u_{i,t}\) – (1)
\(r (N \times 1)\)은 수익률, \(f_t(K \times 1)\)는 수익률에 영향을 끼치는 잠재 위험 변수(latent risk factor)이다. KPS에서는 이 \(f_t\)의 계수에 해당하는 factor loading을 \(\beta (N \times K)\)라는 함수로 표현했는데,
\(\beta(z_{i,t-1})' = z_{i,t-1}'\Gamma\) – (2)
이렇게 종목의 특성을 나타내는 \(z(P \times 1)\)에 대한 선형 함수이다. 즉, 잠재 변수의 계수(\(\beta\))가 종목 특성값이 변함에 따라 함께 동적으로 변한다는 것이다.
이를 위해 차원감축 기법은 필수적인데, 결국 시장의 정보를 압축하여 잠재 변수를 알아내야 하는 것이기 때문이다. 가장 널리 알려져있는 차원감축 기법은 PCA로, 분산이 최대가 되게 회전을 통하여 정보를 압축하는 방법이 있다. 이 논문은 PCA 대신 오토인코더를 사용하여 선형성을 일반화한다. non-linear 함수를 여러 층 쌓아 bottleneck에서 정보를 압축하는 방식으로, PCA가 오토인코더의 특이한 케이스라고 볼 수 있는 것이다. 하지만 PCA와 오토인코더 모두 비지도학습 기법으로, 바닐라 기법은 외부 정보를 압축 과정에서 사용하지 못한다는 문제점을 가지고 있다. 그렇기 때문에 KPS에서는 IPCA(Instrumental PCA)를 사용하여 instrumental variable에 기반한 조건부 factor 가중치를 계산하는 법을 제안하였다. 이 논문에선 그와 비슷하게 conditional autoenencoder를 사용해 외부 정보를 factor loading에 녹여내고 있다.
해당 기법으로 만들어진 모델은 각 종목뿐 아니라 포트폴리오에 대해서도 risk-return tradeoff를 설명하고, valid asset pricing model로서 anomaly 포트폴리오의 가격 또한 통계적으로 유의미하지 않은 오차 내에서 가격 결정을 한다고 주장한다. stochastic discount factor를 찾기 위한 비모수모형과 동치이며, 무차익원리를 가정한다. 모든 것은 out-of-sample로 이루어져 머신러닝 프로세스를 차용했다.
Methodology
Autoencoder and PCA
직관적으로 PCA가 오토인코더의 특이 케이스라는 것은 이해하기가 쉽다. 오토인코더에 1개의 은닉층이 있고 선형활성화함수를 사용한다면 그것이 바로 PCA가 되는 것이기 때문이다. 여기서 층을 늘리고 다양한 활성화함수를 사용한다면 PCA를 넘어서 더 복잡한 함수를 구현할 수 있는 것이며 데이터에 존재하는 더 복잡한 구조를 은닉층 사이의 관계로 모델링할 수 있는 것이다.
Conditional Autoencoder and IPCA
비지도학습 접근법을 사용하면 시장 구조 정보를 효율적으로 학습할 수 있지만, 수익률 이외의 데이터를 conditioning information으로 사용할 여지가 없다는 단점이 있다. KPS는 외부 정보를 사용해 fator loading을 종목 특성의 선형 함수로 추정하여 동적으로 업데이트 하였다. (IPCA 사용) 이렇게 종목 특성 등 외부 정보를 사용하게 되면 factor loading을 더 정확히 추정할 수 있을 뿐 아니라 그 loading을 가지는 잠재 팩터의 질도 향상됨을 보였다. 본 논문은 IPCA 사용을 통해 가정한 beta와 z간의 선형 관계를 일반화여 아래의 모델을 제안하였다.
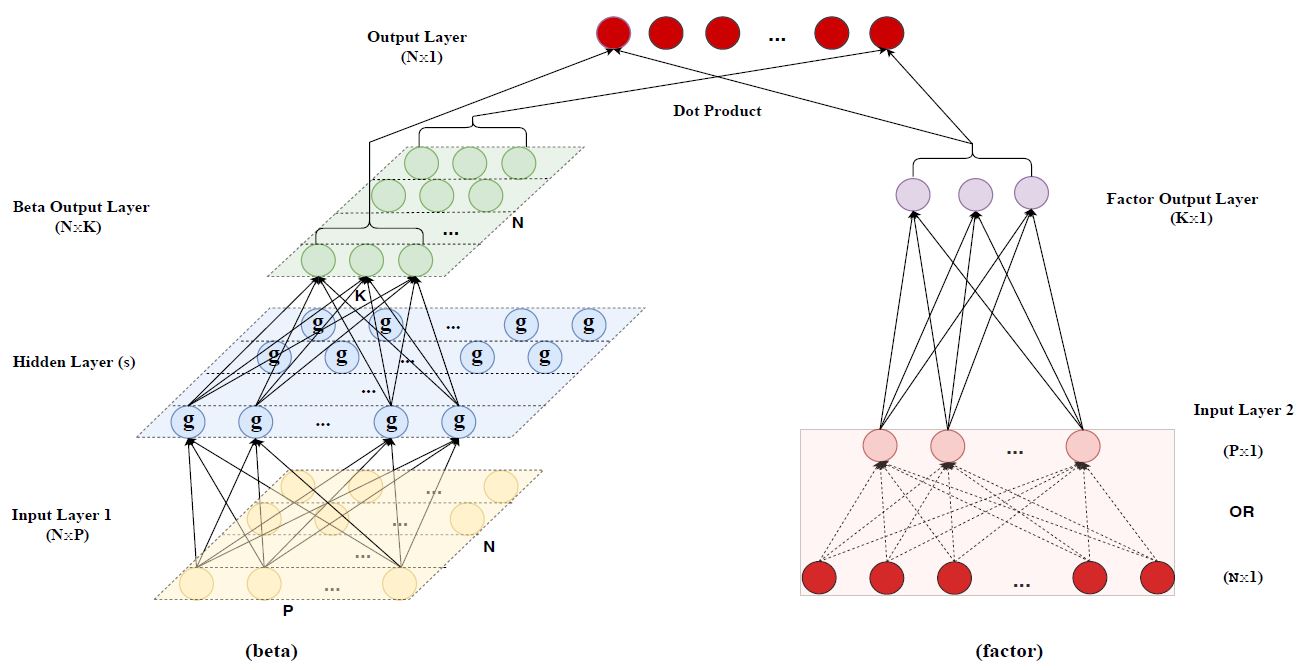
크게 왼쪽과 오른쪽 두 부분으로 나누어져 있는 것을 볼 수 있다. 합쳐지기 전 왼쪽 모델은 factor loading을 계산하는 모델이고 오른쪽에 있는 것은 latent fator를 계산하는 모델이다. 맨 마지막 (제일 위쪽)에선 (1)의 수식처럼 latent factor와 그 loading을 dot product하여 수익률을 재현한다.
Beta
먼저 왼쪽 beta를 계산하는 부분을 살펴보자. 인풋은 \(N \times P\) 행렬로, N개의 종목 각각에 대한 P개의 종목 특성값을 원소로 가지는 행렬이다. 이것을 뉴럴 네트워크 모델에 입력하여 \(N \times K\) 행렬이 되게 압축한다. K는 본 논문에서 가정하고 있는 잠재 팩터의 개수이기 때문에 모델 오른쪽 factor 계산하는 모델에서 나온 factor값과 조합하여 종목의 수익률을 만들게 된다.
Factor
오른쪽 부분에는 2가지 옵션이 존재한다. 먼저 인풋에 개별 주식의 수익률을 넣는다면 오른쪽 부분 한정 standard autoencoder와 비슷한 형태가 된다. (오른쪽 밑의 빨간색 부분) 오토인코더가 학습하면서 수익률간의 관계를 보라색 부분에 저장하게 될 것 뿐 아니라 이 보라색 뉴런이 포트폴리오를 뜻하게 되는 것이다. (종목의 선형조합)
위와 비슷하게 인풋에 개별 주식이 아니라 각 특성에 따라 구성된 포트폴리오의 수익률을 넣을 수 있다. 즉 이제는 인풋이 \(N \times 1\)에서 \(P \times 1\)이 되는 것이다. 이렇게 하면 더 이상 오토인코더가 아니게 된 것처럼 보이는데, 이 옵션을 택하는 것의 장점은 다음의 3가지가 있다.
- 모델 경량화
모델 경량화 자체가 논문의 목적은 아니지만 모든 종목을 쓰는것에서 P개의 특성만 쓰게 된다면 인풋의 크기가 줄면서 업데이트 해야하는 파라미터의 수가 확연히 줄어들게 된다. 즉 포트폴리오를 만드는 과정을 일종의 전처리로 보는 것인데, 이럴 경우 모델은 다시 오토인코더의 형태를 띄게 된다. 위 그림 오른쪽 밑 네모 박스 안 OR를 무시하고 은닉층이 하나 추가된 것으로 본다면 인풋과 아웃풋 둘 다 종목의 수익률이 되는 것이다.
- 패널 임밸런스 해결
이 논문에서 사용하는 종목은 대략 3만개 정도인데, 평균적으로 한 달 내내 수익률 정보를 가지고 있는 종목은 6천개정도밖에 안된다고 한다. 즉, 개별 종목의 수익률을 인풋으로 사용할 경우 평균적으로 24000개의 종목에 대한 데이터는 없는 상태로 모델을 구축해야 한다는 것이다. 반면, 종목 특성을 기반으로 포트폴리오를 만든다면 해당 기간에 데이터가 있는 종목들로 포트폴리오를 만들 수 있어 모든 기간에 대해 데이터가 없는 일은 발생하지 않는 것이다.
- 기존 금융경제학자들이 좋아할 수도 있음
새로 제안하는 오토인코더 기반 모델과 기존 금융 산업에서 사용하는 종목 특성 기반 포트폴리오 분석 컨텍스트와의 접점을 만들 수 있다. 특히 KPS에서는 개별 종목에 대한 조건부 선영 팩터모델이 그 종목 특성 기반 포트폴리오의 정적 팩터 분석으로 나타낼 수 있다는 걸 주장했다.
Experiments
Data
CRSP에서 NYSE, AMEX, NASDAQ의 모든 종목에 대해 1957년 3월부터 2016년 12월까지 총 60년치 데이터를 사용했다고 한다. 또한, conditioning을 위해 94개의 종목 특성을 사용했다. 그 중 61개는 1년에 한번, 13개는 분기별, 20개는 월별로 업데이트 되는 수치이다. 94개의 전체 리스트와 선정 방법은 GKX에서 볼 수 있다. lookahead bias를 피하기 위해서 rebalance month 한달 전까지 구할 수 있는 정보에 기반해서 데이터셋을 만들었다고 한다. 총 3만여개의 종목, 한달에 6200개가 넘는 종목으로 모델을 만들었다. 1957~1974 18년동안을 training, 1975~1986 12년동안을 validation, 1987~2016 10년간을 test set으로 사용했다.
Models
비교를 위한 모델로는,
- PCA
- IPCA
- 4개의 conditional autoencoder 모델 (은닉층과 뉴런 수에 차이를 두어 모델을 여러개 만듬)
- 기존에 알려진 팩터로 만든 benchmark 포트폴리오 (Fama-French 5 factor model) 를 사용하였다.
Training
학습 정보는 다음과 같다.
- Loss: L2
- Regularisation: L1, Early stopping, Ensemble
- Optimisation: minibatch SGD, batch-norm
Performance Evaluation
KPS에서는 test data에 대한 total \(R^2\)와 pred \(R^2\)를 사용하였기 때문에 이 논문에서도 같은 metric을 사용하였다. 각 metric의 정의는 다음과 같다.
\[R^2_{total} = 1- \frac{\sum_{(i,t) \in OOS}(r_{i,t} - \hat{\beta}_{i,t-1}'\hat{f}_{t})^2}{\sum_{(i,t) \in OOS}r_{i,t}^2}\] \[R^2_{pred} = 1- \frac{\sum_{(i,t) \in OOS}(r_{i,t} - \hat{\beta}_{i,t-1}'\hat{\lambda}_{t-1})^2}{\sum_{(i,t) \in OOS}r_{i,t}^2}\]\(\hat{\lambda}_{t-1}\)은 t-1까지 \(\hat{f}\)의 평균값이다.
통계적 metric 이외에도 실제 이 모델을 사용한 투자 performance까지 사용하였다.
Results
결과적으로 \(R^2_{total}\)은 IPCA가, \(R^2_{pred}\)는 conditional autoencoder계열 모델이 다른 모델에 비해서 우수한 성적을 보였다. 위의 인풋에 대한 두가지 옵션 중에선 포트폴리오를 사용한 모델이 더 좋은 성적을 내었다. 수익률 측면에선.. 동일비중일 경우 2.68, 가치가중일 경우 1.53의 샤프 지수를 보여주었다. (항상 그렇듯 결과는 별로 관심없음)
Risk vs Mispricing
단골주제. 특히 Booth여서 더 그러는 것일 수도 있다. 기본적인 주장은 수익률 예측성을 모두 종목 특성, 즉 위험 팩터에서 기인했다는 것이다. 이를 위해서 intercept test를 시행하였다. 결국 종목 특성에 기반해서 만든 95개의 포트폴리오 수익률을 각 모델 (위에 비교대상 모델)이 얼마나 설명하느냐, 그리고 설명하지 못한 부분 (잔차)의 평균은 통계적으로 0과 다른가 등을 검정하는 것이다. 쉽게 말해서 알파가 얼마나 있느냐를 확인하는 과정인데, 알파란 위험에 노출되지 않고서도 얻을 수 있는 수익률, 즉 기울기에 영향을 받지 않는 intercept인 것이고, 수학적으로는 모델이 price한 자산의 가격과 실제 가격의 차이, 즉 잔차가 되는것이다. 95개의 포트폴리오 수익률과 모델의 예측값을 비교했을 때, 벤치마크라고 설정한 FF모델은 t-statistics > 3 인 경우(잔차가 통계적으로 유의미하게 0이 아닌 경우)가 37개인 반면, conditional autoencoder는 대부분 10개도 안되는 것으로 보아 이 논문에서 제안하는 모델이 risk-return을 더 잘 설명한다고 주장한다.
My Conclusion
재밋어보이고 한국 데이터로 한다면 정말 좋을거같아서 데이터를 모아보려고 했는데 생각보다 characteristics가 너무 많고 지표로 삼으려 했던 KOSPI200의 역사가 짧아 이 논문의 모델을 그대로 구현해 볼 수 있을까 의문이 있다. 솔직히 엄청 힘들 것 같음. 어쨌든 읽으면서 많은 것을 배울 수 있었다.
Leave a comment