[Paper Review] Meta-Learning Symmetries by Reparameterization
Arxiv 링크
삼성 ai fair에서 첼시 핀이 설명해준 논문. 2021년 ICLR에 제출했다고 한다. 내가 바보같은 질문 했는데도 잘 대답해준 첼시 님짱. 논문도 진짜 멋있음. 이게 논문이지.
논문을 읽기 전에 알아야하는 내용이 생각보다 많다. Meta-Learning, Equivariance, Group Action 중 하나라도 익숙하지 않은게 있다면 처음부터 다 읽는 것을 추천하고, 모두 다 알고 있다고 생각한다면 Encoding and Learning Equivariance부터 읽으면 된다. 시작합시다.
task-specific 뉴럴넷 아키텍쳐를 디자인할 필요 없이 데이터를 통해서 모델의 equivariance를 학습하는 방법을 제안함. Reparameterization을 통해서 NN 레이어를 ‘구조’와 ‘값’에 해당하는 두 부분으로 나누었고, meta-learning framework를 적용하여 모델이 가져야 할 equivariance는 ‘구조’에 해당하는 부분이, task-specific한 파라미터 값은 ‘값’에 해당하는 부분이 각각 학습하게 함으로써 사람의 개입을 최소화하려고 함. 멋있쥬.
미리 알아야 하는 개념이 몇가지 있다. 메타러닝, equivariance, reparameterization 등이다. 하나씩 살펴보기로 하자.
- Meta-Learning
메타러닝은 학습하는 방법을 학습하는 것이다. 즉, 파라미터의 초기값, 러닝레이트 등의 하이퍼파라미터를 학습하여 (메타학습) 실제 모델 학습을 진행하거나 메타데이터를 이용하여 학습 방법을 학습한다.
- Equivariance
아래에서 더 정확하고 엄밀히 다룰 것이나, 직관적으로 설명하자면, 함수가 ‘equivariant’하다, 혹은 함수가 ‘equivariant map이다’라고 하는 것은 함수를 통과하기 전 인풋의 transformation이 함수를 통과하고 난 결과의 transformation과 같다는 이야기이다. 예를 들자면, CNN에 인풋을 90도 회전시켜서 넣으면 통과한 feature map 또한 90도 회전하여 나온다는 것으로 이해할 수 있다.
- Reparameterization
함수값을 구하기 위해 주어진 파라미터를 그대로 사용하는 것이 아니라 같은 결과를 내는 다른 파라미터를 사용하는 것을 말한다. 예를 들면 정규분포값을 샘플링할 때 평균과 분산이 주어지면 그 정규분포를 만들어서 샘플링하기보다는 표준정규분포에서 샘플링한 후 평균만큼 이동하고 분산만큼 scale해주는 방법을 많이 사용하는 것을 생각하면 된다.
Introduction
뉴럴넷 모델은 특정한 translation에 대해서 equivariant한 경우가 많은데, CNN의 경우 인풋이 뒤집히거나 회전되면 아웃풋도 똑같이 뒤집히거나 회전되는 것을 볼 수 있다. 이미지나 음성 데이터에서 어떠한 피쳐 정보를 학습할 수 있을지 생각해봤을 때 translation equivariant한 모델 구조를 사용하는 것은 상당히 데이터의 특성에 잘 맞는 선택이라고 볼 수 있다. 하지만 이러한 데이터의 구조를 알아내는 것이 항상 쉬운 것은 아니다. 또한, 그 구조를 알아냈다고 하더라도 뉴럴넷 모델에 반영하는 것은 또 다른 어려운 문제인 것이다. 보통 현업에서는 모델 구조에 이 사항을 반영하기 어렵기 때문에 data augmentation을 통해 모델 파라미터를 변화시켜서 equivariance를 학습하게 한다. 이 논문에서는 data augmentation을 사용하지 않고 모델 내부에서 equivariance를 학습하여 적용하는 방법을 제안한다.
Equivariance를 잡아내기 위해서는 모델 내부의 파라미터의 공유 패턴 (paramter sharing pattern)을 학습해야 한다. 이를 위해서 뉴럴넷 레이어를 ‘파라미터 공유 패턴’ (구조) 과 실제 파라미터값 (값)으로 나누어서 각각을 따로 학습하게 한다.
Preliminaries
먼저 알아야 할 개념들. MAML을 계승한 메타러닝 알고리즘, 군과 군 작용, equivariance (등가성질) 에 대해서 더 자세히 알아보자.
- Gradient-Based Meta-Learning
Task distribution \(p(\mathcal{T})\)가 있다고 하면 각 task는 training/validation 데이터셋 {\(\mathcal{D}^{tr}_{i}, \mathcal{D}^{val}_{i}\)} 을 갖는다. MAML에서 제안하는 메타러닝 프레임워크에는 내부 룹과 외부 룹이 있다. 파라미터 \(\theta\), 손실함수 \(\mathcal{L}\), 러닝레이트 \(\alpha\)를 가지는 모델이 있을 때 내부 룹에서는 task-specific 데이터셋을 가지고 \(\theta\)를 찾는다. 우리가 보통 알고있는 모델 학습 과정이라고 생각하면 된다. 학습하는 방법은 그레디언트 기반 업데이트 알고리즘을 사용한다. 수식으로는 \(\theta'=\theta-\alpha\nabla_{\theta}\mathcal{L}(\theta,\mathcal{D}^{tr})\) 이렇게 표현할 수 있다. 외부 룹에서는 validation set을 사용하여 \(\theta\)의 초기값을 학습한다. 위에서 정의한 \(\theta'\)를 사용했을 때 손실함수값을 최소화시키는 방향으로 업데이트를 진행하는 것이다. 즉, 외부의 메타러닝 룹에서는 \(\theta \leftarrow \theta-\eta\frac{d}{d\theta}\mathcal{L}(\theta',\mathcal{D}^{val})\)을 사용한다. MAML에서는 이와같이 \(\theta\)의 초기값을 설정하는 것에 중점을 두었지만 다른 하이퍼파라미터를 찾는 것도 비슷한 프레임워크를 사용할 수 있다. 이 논문에서는 Gradient-Based Meta-Learning방법을 사용하여 파라미터 공유 패턴을 학습한다.
- 군과 군 작용
수학에서 대칭성이나 equivariance는 추상대수학의 군과 군 작용 분야에서 주로 다루어진다. 여기서 정의하는 군이란 결합법칙이 성립하는 이진연산에 대하여 닫혀있는 집합 (\(G\)) 을 일컫는데, 이 집합 안에 항등원이 존재해야 하며 모든 원소는 역원을 가지고 있어야 한다. 예를 들자면 \((\mathbb{Z}, +)\)가 있을 수 있다.
군 \(G\)는 집합 \(X\)에 ‘작용’ 할 수 있는데 (Group \(G\) can act on a set \(X\)), 그 작용 (action) \(\rho:G\rightarrow Aut(X)\)은 각 \(g\in G\)에서 \(X\)의 transformation으로 매핑해주는 함수이다. 여기서 \(\rho\)는 준동형사상(homomorphism, \(\rho(gh)=\rho(g)\rho(h) \enspace \forall g,h\in G\)) 이어야 하고, \(Aut(X)\)란 \(X\)에 대한 자기동형사상이다. 자기동형사상이란 \(X\) 자신에서 자신으로 매핑하는 전단사 준동형사상 (bijective homomorphism) 이며, 어떤 대상의 ‘대칭성’을 나타낸다고 이해하면 된다.
정리하자면 \(\rho\)는 \(G\)에 있는 어떠한 원소를 받으면 ‘사상’을 출력해주는 것인데, 이 사상은 자기동형사상이기 때문에 \(\rho\)를 통하면 \(G\)에 있는 원소가 \(X\)가 가지고 있는 하나의 ‘대칭성’을 반환해준다고 생각할 수 있는 것이다. 만약 \(X\)가 군이 아니라 집합이면, 자기동형사상은 전단사를 만족하기만 하면 된다. 이 경우에도 대칭성을 나타낸다.
이 논문에서는 어떤 \(g\in G\) 에 대해서 \(gx\coloneqq\rho(g)(x)\) 라고 줄여쓰기로 한다. 군 작용의 간단한 예시는 자기 자신에게 작용하는 것이다. 위에서 \(X=G\)라고 놓으면 된다. \((\mathbb{Z},+)\)의 경우에는 어떤 \(g,x\in \mathbb{Z}\)에 대해서 작용 \(gx=g+x\)로 정의해보자. \(g\)가 들어가면 \(\rho(g)(\cdot) = g+\cdot\) 이라는 자기동형사상을 얻는 것이다. (람다 노테이션을 쓴다면 \(\rho(g)=\lambda x.x+g\)) 정수가 찍혀진 수선이 \(g\)만큼 수평이동한 것이라고 생각하면 된다. 수평이동하는 정도는 어떠한 정수든 될 수 있다는 것을 떠올리자.
만약 군 \(G\)가 벡터 공간 \(V\)에 작용한다면 그 작용을 표현 (representation)이라고 하고, \(\pi:G\rightarrow GL(V)\)로 나타낸다. \(GL(V)\)는 벡터공간 \(V\)의 일반선형군 (General Linear Group) 이며, 가역 선형변환이 이루는 군이다. (Invertible Linear Maps on \(V\)) 벡터가 이산적이라면 벡터의 원소는 이산적인 인덱스를 가지고 있고, 만약 정수에서 정의된 군 작용이 있다고 하면 이를 벡터의 인덱스로 확장시킬 수 있다. 자연스럽게 이 군 표현은 \((\pi(g)v)[i]\coloneqq v[g^{-1}i]\)로 나타낼 수 있다. 벡터의 원소는 정수값을 가지고 있기 때문에 위에서 정의한 것을 그대로 가져오게 된다면 \((\pi(g)v)[i]=v[g^{-1}i]=v[i-g] \enspace\forall g,i\in\mathbb{Z}\)가 된다.
즉, 위에서 ‘정수가 찍혀진 수선이 수평이동’ 한 것을 벡터의 인덱스로 가져오게 되면 ‘벡터의 인덱스를 이동’하는 것으로 확장시킬 수 있는 것이다. \(g\)가 1이라면 해당 ‘군 표현’을 사용하여 \([0,1,2,3,0,0]\)을 \([0,0,1,2,3,0]\)이런 식으로 옮기는 것이다.
- 등가성질 (equivariance)과 합성곱(Convolution)
등가성질
함수가 어떤 변환에 대해서 등가성을 가진다 (A function is equivariant to a transformation)이라고 하면, 함수의 인풋을 변환하는 것과 함수의 아웃풋을 변환하는 것이 똑같은 것을 일컫는다. 여기서 말하는 ‘변환’이 어떤 것인지 살펴보는 것이 필요하다. 이를 위해서 위에서 짚어본 군 작용의 개념이 등장한다.
뉴럴넷 레이어를 주로 볼 것이기 때문에 뉴럴넷 레이어 \(\phi:\mathbb{R}^n\rightarrow \mathbb{R}^m\)을 예시로 들어보자. \(\mathbb{R}^n\)과 \(\mathbb{R}^m\) 각각에 작용하는 군 \(G\)의 두 표현 \(\pi_1,\pi_2\)가 있다고 생각하자. \(\phi\)의 인풋은 \(n\)차원, 아웃풋은 \(m\)차원이기 때문에 \(\pi_1(g)\)와 \(\pi_2(g)\)는 각각 인풋과 아웃풋에 가해지는 변환을 나타내는 것이라고 생각하면 된다. 다시 한번 정리하자면, \(g\)가 들어오기 전 \(\pi_1\)이나 \(\pi_2\)는 \(g\)를 변환으로 매핑해주는 ‘표현’이고, \(g\)가 들어온 \(\pi_1(g)\)나 \(\pi_2(g)\)는 \(GL(V)\)에 속하는 ‘변환’이 되는 것이다. 이제 등가성질을 좀 더 엄밀히 정의할 수 있게 되었다.
뉴럴넷 레이어 \(\phi\), 벡터공간에 작용하는 군 \(G\), 그 표현 \(\pi_1\)과 \(\pi_2\)가 있을 때, 어떤 \(g\in G, v\in \mathbb{R}^n\)에 대해서\(\phi(\pi_1(g)v)=\pi_2(g)\phi(v)\)를 만족시키면, \(\phi\)는 그 변환에 대해서 \(G\)-등가성 (\(G\)-equivariant)이라고 한다.
만약 \(\pi_2\equiv id\) 이면 (\(g\)가 무엇이 들어오든 ‘인풋을 그대로 반환해주는 변환’으로 매핑한다.) \(\phi(\pi_1(g)v)=\phi(v)\)가 되며, 이를 불변성 (invariance)라고 한다. 즉, 불변성은 등가성의 특이 케이스인 것이다. (Invariance is a type of equivariance)
합성곱
딥러닝 모델은 뉴럴넷 레이어를 여러 층 쌓은 것이기 때문에 함수합성으로 이루어진다고 볼 수 있다. 함수합성 자체는 등가성질을 만족하며, 점별 연산인 활성화함수들 또한 등가성실을 만족하기 때문에 이 논문에서는 하나의 linear layer에 대해서 등가성질을 살펴본다.
군-합성곱(Group Convolution)에 대해서 알아보자. 이는 우리가 흔히 알고 있는 합성곱을 일반화한 것이다. 군 \(G\)에 대해서 \(G\)-합성곱 (\(G\)-Convolution)은 각 \(g\in G\)에 대해서 합성곱의 필터를 변환시킨 다음 인풋과 변환된 팔터를 내적하는 것이라고 생각하면 된다. 일반적인 ‘합성곱 뉴럴넷’에서 쓰이는 합성곱은 필터를 ‘이동’시킨것이다. 아래의 그림을 보면 알 수 있다. CNN 필터를 적용하는 것을 모두 펴서 행렬곱으로 인식하면 이해가 빠를 것이다. 파라미터 값의 위치를 이동시켜서 weight matrix 를 만들 수 있기 떄문에 아래에 있는 1-D 합성곱 신경망은 ‘이동’이라는 변환에 등가성질이 있는 것이다.
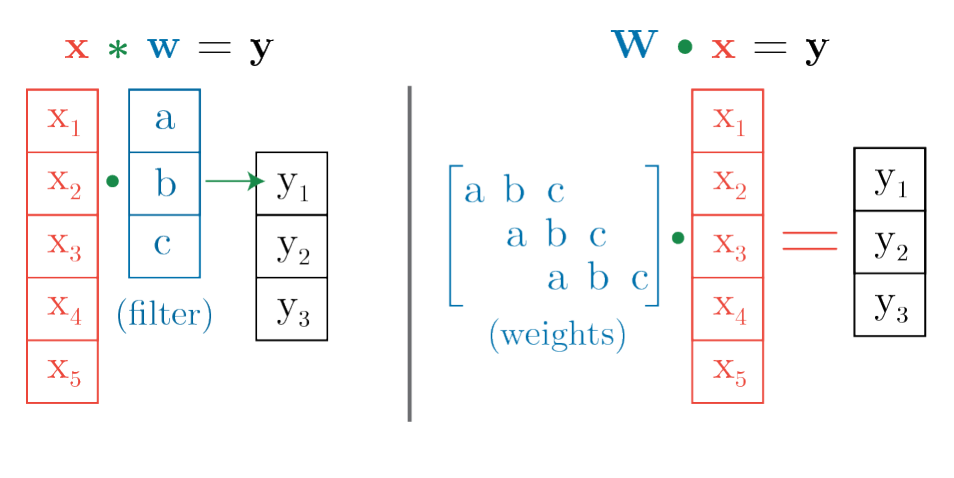
Kondor and Trivedi, 2018에 따르면 linear layer \(\phi\) 가 어떤 군 작용에 대해서 등가성이기 위해서는 iff 그 layer가 군 합성곱이어야 한다는 것을 증명하였다. 즉, \(G\)-등가성 레이어는 인풋 \(v\in \mathbb{R}^n\)을 필터 \(\psi\in\mathbb{R}^n\)를 사용하여 합성해야 한다는 것을 말한다. 정리하자면, 유한 군 \(G=\{g_1,\cdots g_m\}\)이 있다고 할 때
\[\phi(v)[j]=(v\star\psi)[j]=\sum_i{v[i](\pi(g_j)\psi)[i]}=\sum_i{v[i]\psi[g^{-1}_{j}i]}\]으로 나타낼 수 있는 것이다. 여기서 \(\star\)는 합성곱을 나타낸 것이다. 이 논문에서는 fully connected layer등 많이 쓰이고 있는 레이어의 파라미터 공유 패턴을 학습하는 방법을 소개한다. 이 파라미터 공유 패턴을 통하여 군 합성곱을 표현할 수 있고, 즉 등가성 레이어가 만들어지게 된다.
Encoding and Learning Equivariance
Mea-Learning Symmetries by Reparameterization (MSR)이라는 방법을 제안함.
Learnable Parameter Sharing
위에서 본 것처럼 파라미터가 한칸씩 이동한 특정 ‘공유패턴’을 따르는 경우 FC Layer는 위치에 등가한 (equivariant to translation) 합성곱 신경망을 구현할 수 있었다. 이것을 일반화시키면 다른 ‘공유패턴’을 사용한다면 다른 ‘변환에 등가’한 레이어를 만들 수 있을 것이다. 하지만 다른 ‘변환’을 알지 못하기 때문에 reparamterzation을 통하여 이를 학습한다.
Weight matrix \(W\in\mathbb{R}^{m\times n}\) 을 가지고 있는 FC Layer \(\phi:\mathbb{R}^n\rightarrow \mathbb{R}^m\) 는 인풋 \(x\)가 들어왔을 떄 \(\phi(x)=Wx\)로 정의된다. 만약 bias term을 넣고 싶다면 인풋 \(x\)에 값을 1로 가지는 차원을 하나 추가할 수도 있다. 통계학에서 design matrix를 만들 때처럼 말이다. 여기서 reparameterzation을 실시한다. Weight matrix \(W\)를 ‘symmetry matrix’ \(U\)와 \(k\)개의 ‘filter parameter’를 가지는 벡터 \(v\)로 행렬분해를 하는 것이다. 초반에 언급한 ‘구조’에 해당하는 것이 \(U\)이고 ‘값’에 해당하는 것이 \(v\)이다. 행렬분해를 진행하는 방법은 아래와 같다. 사실 아래 내용은 전통적으로 고유값 등을 사용하는 행렬분해보다는 기초적인 연산이라고 생각될 수 있으나 논리적인 연산법이다.
\[\text{vec}(W)=Uv\quad v\in\mathbb{R}^k,\,U\in\mathbb{R}^{mn\times k}\]결과인 \(\text{vec}(W)\in\mathbb{R}^{mn}\)을 reshape하여 처음에 구하고자 하였던 weight matrix \(W\in\mathbb{R}^{m\times n}\)로 만든다. 이 논문에서는 1차원 벡터 \(\text{vec}(W)\)를 행으로 잘라서 reshape을 진행하였다. 직관적으로 \(U\)는 \(W\)가 가지고 있는 파라미터 ‘공유패턴’을 학습하게 될 것으로 기대할 수 있다.
이 ‘symmetry matrix’는 층당 \(mnk\) 의 엔트리 수를 가져 상당히 큰 편이기 때문에 이 논문에서는 Kronecker factorization을 사용하여 계산 시간을 줄였다. 뿐만 아니라, 모든 equivariance를 다 학습하게 하는 것은 비효율적일 수 있기 때문에 우리가 미리 알고 있는 equivariance는 사람의 개입을 통해 모델에 주입시키고 사람이 개입하지 않은 나머지 equivariance를 학습하게 할 수도 있다. 예를 들면 위에서 weight matrix를 만드는 과정에서 weight matrix 대신 convolution filter를 학습하게 한다면, translation equivariance를 미리 모델에 주입시키는 것과 같은 효과이다. 모델에 특정 equivariance에 대한 bias를 주는 대신 파라미터 수가 획기적으로 줄게 되는 것이다. 만약 이미지 데이터를 다루고 있다면 tranlation equivariance는 모델이 필수적으로 학습해야 하는 것이기 때문에 좋은 성능을 효율적으로 달성할 수 있게 할 것이다.
Parameter Sharing and Group Convolution
Symmetry matrix \(U\)를 잘 선택한다면 \(v\)라는 필터를 사용하는 어떠한 group convolution도 나타낼 수 있게 된다. 이 논문은 같은 내용의 아래 proposition을 증명하였다.
Proposition1. 유한 군 \(G=\{g_1\cdots g_m\}\)이 있을 때, 모든 \(v\in \mathbb{R}^n\)에 대하여 \(\text{vec}(W)=U^Gv\) 를 weight로 가지는 레이어가 인풋 \(x\in\mathbb{R}^n\)에 가해지는 \(G\)-합성곱을 나타낼 수 있게 하는 \(U^G\in \mathbb{R}^{mn \times n}\)이 존재한다. 또한, 위에서 언급한 \(U^G\)가 주어졌을 때 어떤 \(v\in\mathbb{R}^n\)에 대하여 weight matrix \(\text{vec}(W)=U^Gv\)를 통해 어떠한 \(G\)-합성곱도 표현될 수 있다.
즉, \(U\)는 각 \(g\in G\)에 대응되는 대칭변환 \(\pi(g)\)에 대한 정보를 저장할 수 있고, \(G\)-합성곱 중에 어떠한 필터 ‘공유패턴’을 가져야 하는지를 알아낼 수 있다. 예를 들어서 \(G\)를 Permutation group \(S_2\)로 지정했다고 생각하자. \(S_2\)는 두 객체의 순서를 바꾸지 않는 것과 바꾸는 것, 두개의 원소로 이루어진 군이다.
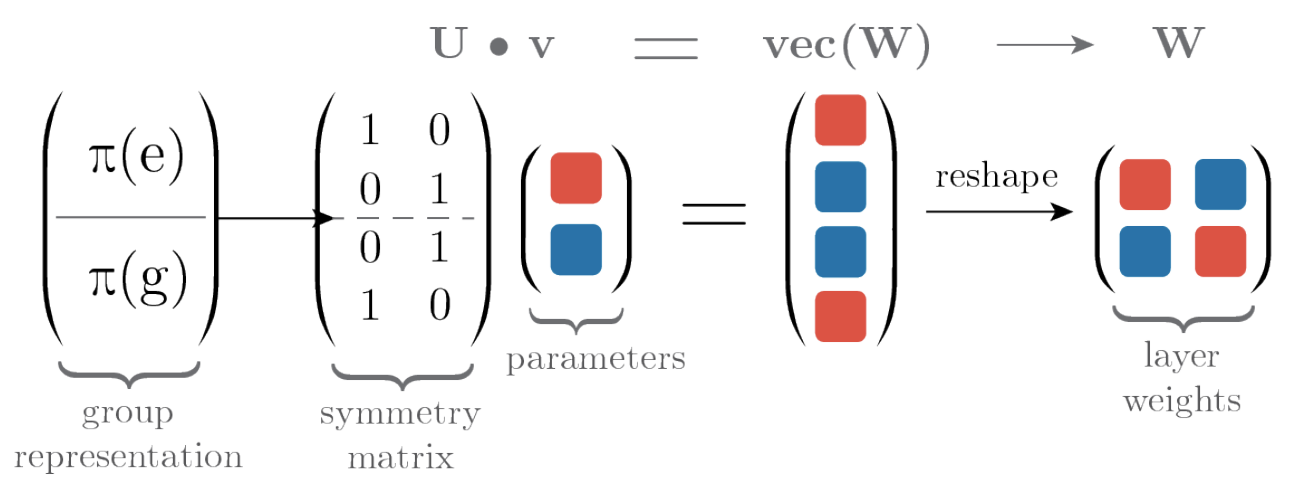
순서를 바꾸지 않는 것과 바꾸는 것 두 변환은 \(\pi(e)\)와 \(\pi(g)\)로 각각 나타내어졌으며, 행렬의 형태로 표현한다면 symmetry matrix상단과 하단에 나와있는 것 처럼 두 원소의 위치에 대한 변환으로 나타내어질 것이다. 이 ‘구조’에 해당하는 행렬이 \(U\)가 되는 것이다. 여기에 ‘값’에 해당하는 \(v\)가 곱해진다. 위와 같이 만약 ‘올바른’ \(U^G\)가 주어진다면 \(v\)는 \(G\)-합성곱에서 합성곱 필터가 될 것이다. 즉 구조와 값에 해당하는 파라미터를 Meta-Learning 프레임워크에 적용하여 외부 룹과 내부 룹에서 각각을 학습하는 형태를 떠올릴 수 있는 것이다. 모델을 학습할때 ‘올바른’ 파라미터 초기값이 주어진다면 최적의 파라미터를 학습할 수 있다는 것과 겹쳐서 생각해보자.
Meta-Learning Equivariances
메타러닝은 여러 task가 공유하는 구조를 학습하는 것이라고 이해할 수 있다. 이 task의 분포 \(p(\mathcal{T})\)가 있을 때 이 분포는 특정 대칭성을 포함하고 있다고 생각한다. 즉, 각 task별로 만들어진 모델들은 특정 equivariance를 공유하고 있다고 생각하는 것이다. 이미지를 예로 들면 위치 등가성질이 이미지 분류 문제나 이미지 생성 문제, 이미지 segmentation문제를 푸는 각각의 모델에 모두 녹아져있다고 생각하는 것과 같은 것이다. 합리적인 가정이라고 할 수 있다. 이 공유되는 equivariance를 찾기 위해서 앞서 살펴본 Gradient Based Meta-Learning 프레임워크를 사용한다. 아래의 그림에 대략적인 설명이 되어있다.
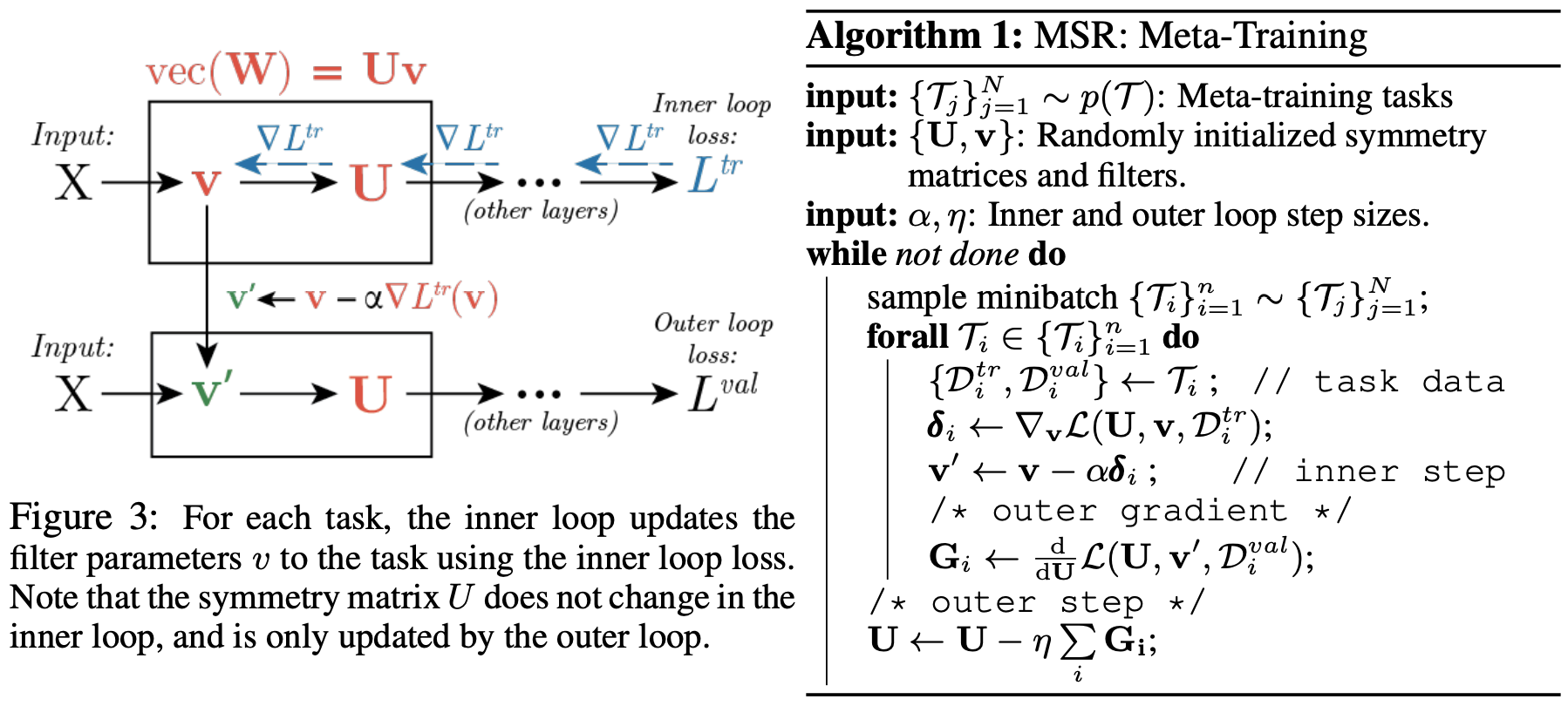
\(L\)개의 레이어를 가진 네트워크가 있다고 하면 각 레이어의 symmetry matrix와 필터 파라미터를 한데 모아 \(\bold{U},\bold{v}\leftarrow\{U^1,\cdots U^L\},\{v^1,\cdots,v^L\}\)라고 하자. 위에서 논의한 바대로 task와 관계없이 공유되는 특성을 알고싶지 때문에 symmetry matrix는 \(p(\mathcal{T})\)에 따라서 변하지 않아야 한다. 즉, \(\mathcal{T}_i\sim p(\mathcal{T})\)를 따라서 반복되는 ‘내부 룹’ 에서는 \(\bold{U}\)를 고정한 채 task에 맞는 데이터셋을 사용해서 \(\bm{v}\)만을 업데이트 하는 것이다.
\[\bold{v}'\leftarrow \bold{v}-\alpha\nabla_{\bold{v}}\mathcal{L}(\bold{U},\bold{v},\mathcal{D}^{tr}_i)\]메타학습을 진행하는 ‘외부 룹’에서는 위에서 정의한 \(\bold{v}'\)를 사용했을 때의 validation loss를 계산하여 \(\bold{U}\)를 업데이트 한다. 당연히 \(\bold{U}\)이외에도 \(\bold{v}\)의 초기값 등의 하이퍼파라미터를 여기 ‘외부 룹’에서 학습하는 것도 가능하다.
\[\bold{U}\leftarrow \bold{U}-\eta\frac{d}{d\bold{U}}\mathcal{L}(\bold{U},\bold{v}',\mathcal{D}^{val}_i)\]위와 같은 메타학습이 끝난 후에는 \(\bold{U}\)를 고정시킨 후 새로운 task \(\mathcal{T}_k\sim p(\mathcal{T})\)에 대해서 ‘내부 룹’ 만을 사용하여 \(\bold{v}\)만을 학습시킨다.\(\bold{U}\)와 \(\bold{v}\)를 분리했기 때문에 각 레이어에서 학습해야 하는 파라미터의 개수가 줄어들었고, 일반화성능의 개선을 기대할 수도 있다.
Experiments
이 모델을 가지고 여러 실험을 해봤는데, 그 중 재밌었던 것을 소개하려고 한다. Data Augmentation과 관련된 실험이다. Data Augmentation이란 모델에게 불변성(invariance)을 심어주기 위해서 일부러 인풋을 여러가지로 변환시키는 것을 의미한다. 인풋은 변환되었으나 아웃풋 결과가 같다면 모델은 해당 변환에 대해서 불변성을 갖게 될 것이다. 하지만 로보틱스 등의 task의 경우에는 data augmentation이 테스트타임에서 불가능할 수가 있다. 그렇기 때문에 첼시는 메타학습시에만 data augmentation을 하여 모델이 invariance를 잘 잡아내는지 보았다. 위에서 invariance는 equivariance의 일종이라고 했다. MSR을 사용하면 둘 다 잡아내어야 하는 것이 맞다.
MSR을 이용하여 메타학습시에는 data augmentation을 통해 모델에 equivariance를 학습하게 한 다음 메타테스트때에는 data augmentation 없이 학습을 진행시키는 실험을 한 것이다. 자세히 살펴보자면, 각 task는 학습과 검증셋, \(\mathcal{T}_i=\{\mathcal{D}^{tr}_i,\mathcal{D}^{val}_i\}\)을 가지고 있는데, data augmentation을 \(\mathcal{D}^{tr}\)에만 적용하여 새로운 데이터셋을 만든 것이다.(\(\hat{\mathcal{T}}=\{\mathcal{D}^{tr}_i,\hat\mathcal{D}^{val}_i\}\)) 즉, 메타러닝 모델은 augment가 되어있지 않은 데이터를 학습하여 augment가 되어있는 검증셋에서 성능을 평가받아야 하고, 이 과정에서 MSR을 사용해 equivariance를 모델에 주입시키겠다는 것이다. 학습시에는 augmented data를 보지 않았으니 equivariance를 직접적으로 경험한 것이 아니다.
결과는 세팅에 따라 차이가 있지만 MSR의 장점이 여러모로 있다고 주장한다.
Discussion
멋쟁이 첼시는 앞으로 연구주제도 던져주는데, 확실히 연산량이 신경쓰였나보다. ‘구조’뿐 아니라 어떻게 효율적으로 해당 구조를 계산해야 하는지를 학습하는 것도 필요할 것이라고 한다. 또한, task-specific equivariance에 대해서도 연구가 더 필요하다는 생각이다.
My Conclusion
첼시님짱 진짜 짱멋있다. 아래는 바보같은 내 질문과 천사같이 답해준 첼시님.

Leave a comment