[Paper Review] Efficiently Sampling Functions from Gaussian Process Posteriors
Arxiv 링크
ICML2020에 임페리얼(!) 이랑 UCL의 Marc Deisenroth와 연구진이 투고한 논문. 갑자기 GP에 꽂혀서 읽어보게 됨. GP Posterior로 나타내어지는 분포에서 실질적으로 tangible한 함수를 효율적으로 샘플링하는 방법을 제안함. 시작
Introduction
GP는 데이터를 잘 나타낼 수 있는 함수의 분포를 추정하는 방식이다. 인풋 데이터를 하나의 랜덤 변수로 생각하여 각 데이터쌍의 관계를 모델링하는 형식으로 진행된다. Covariance function으로 GP prior를 정의하고 트레이닝 데이터의 정보를 함수에 포함시켜서 GP posterior 분포를 만든다. 이 때 결과물은 함수의 분포라는 것이 중요한 점이다. Prior/Posterior 개념과 함수 분포의 개념이 함께 등장하기 때문에 GP를 Weight Space, Function Space 양쪽 시각에서 다 바라볼 수 있다. 이 부분은 GP의 교과서인 Gaussian Processes for Machine Learning를 보면 잘 공부할 수 있다.
대부분의 경우 베이지안 방식을 활용하여 얻은 함수 분포는 해석적으로 계산이 불가능한 경우가 많기 때문에 몬테카를로 기법을 사용하지만 GP는 해석적으로 분포를 알아낼 수 있다. 정규성에 대한 가정이 들어가있기 때문이다. 하지만, GP를 통해 결정을 내려야 할때는 (강화학습 등) 분포 자체보다는 분포에서 얻은 명확한 함수를 얻는 것이 더 도움이 된다.
GP 사후분포에서 함수를 찾아내는 것은 trivial한 문제가 아니며, 나이브하게 샘플링을 하는 것은 통계적인 특성을 잘 반영하겠지만 연산량이 상당하다는 문제가 있다. 반대로, 연산량을 줄이는 방법들은 함수를 GP 사후분포에 맞게 샘플링하기가 힘들다는 단점이 있다. 이 논문에서는 GP사후분포에서 함수를 샘플링하는 여러 방법을 비교하고 서로의 단점을 보완하여 효율적인 함수 샘플링 방법을 제안하고 있다. 간략히 설명하면, GP사후분포를 prior와 update로 분해하여 각 항에 맞는 함수 샘플링 방식을 적용한다.
Sampling GP
GP Recap
\(\mathcal{X} \subseteq \mathbb{R}^d\)의 정의역을 가지는 알려지지 않은 함수 \(f: \mathcal{X} \rightarrow \mathbb{R}\)를 생각하자. 또한, 이 함수에서 도출된 \(n\)개의 가우시안 학습 데이터 \(y_i=f(x_i)+\epsilon_i\), \(\epsilon_i\sim \mathcal{N}(0,\sigma^2)\)가 있다고 생각하자.
GP란 임의의 유한한 포인트 \(\bold{X}_*\subseteq\mathcal{X}\)에 대해서 랜덤 벡터 \(\bm{f}_*=f(\bold{X}_*)\)가 가우시안 분포를 따르는 랜덤 함수 \(f\)를 말한다. GP는 평균함수 \(\mu\) 와 공분산함수 \(k\) 로 정의될 수 있는데, \(f\sim\mathcal{GP}(\mu,k)\)라고 한다면 \(\bm{f}_*\sim\mathcal{N}(\bm{\mu}_*,\bold{K}_{*,*})\)는 커널 \(k\)로 정의되는 공분산함수 \(\bold{K}_{*,*}=k(\bold{X}_*,\bold{X}_*)\)를 가지는 다변량 정규분포를 따른다. 흔히 하듯 평균함수를 0이라고 가정하고, 공분산함수는 정상성을 만족한다고 가정하자.
\(n\)개의 포인트 \(\bm{y}\)를 관찰한 후 \(\bold{X}_*\) 에서 정의되는 GP사후분포는 \(\bm{f}_*\mid\bm{y}\sim\mathcal{N}(\bm{m}_{*\mid n},\bold{K}_{*,*\mid n})\)이 된다. 여기서 평균함수와 공분산함수는 아래와 같다.
\[\bm{m}_{*\mid n}=\bold{K}_{*,n}(\bold{K}_{n,n}+\sigma^2\bold{I})^{-1}\bm{y}\] \[\bold{K}_{*,*\mid n}=\bold{K}_{*,*}-\bold{K}_{*,n}(\bold{K}_{n,n}+\sigma^2\bold{I})^{-1}\bold{K}_{n,*}\]위 식의 derivation은 문일철교수님의 유튜브 비디오에 보면 설명이 되어 있다. Joint Normal Distribution을 이용한 선형대수 식 전개를 거치면 된다.
Naive Sampling
위와 같은 \(\bm{f}_*\mid\bm{y}\) 를 샘플링하기 위해서 보통은 표준정규분포 변수를 샘플링한 후 평균과 분산을 이용하여 transform한다. 표준정규분포를 가지는 변수를 \(\zeta\sim\mathcal{N}(0,\bold{I})\)이라 할 때 아래와 같이 샘플링한다.
\[\bm{f}_*\mid\bm{y}=\bm{m}_{*\mid n}+\bold{K}^{1/2}_{*,*\mid n}\zeta\]행렬에 1/2를 씌운 것은 촐레스키분해 등 행렬의 제곱근을 나타내는 것이다. 분명 위와 같이 샘플링하는 것은 이론적으로 완벽하고 수치적인 오류도 없을 것이다. 하지만, \(\bold{K}^{1/2}_{*,*\mid n}\)을 계산하는 것에 벌써 \(\mathcal{O}(*^3)\)의 연산량이 들어간다. 테스트 데이터가 많을수록 역수를 취해야하는 행렬이 커지기 때문에 무척 비효율적이게 되는 것이다. 지금까지 제안된 효율적인 샘플링 기법을 살펴보자.
Function-space approximations to GPs
앞서 GP를 함수분포의 관점에서 볼 수 있다고 했다. 이 관점에서 자연스럽게 나온 샘플링 기법은 Sparse GP이다. 실제 학습 데이터 대신, 데이터의 특성을 잘 반영하는 새로운 점(pseudo inputs)을 가지고 GP 학습을 진행한다.
자세히 설명하면, 적절하게 정의한 inducing locations \(\bold{Z}=\{z_{1},\dots,z_{m}\}\) 에서 함수가 어떠한 특성 \(\bm{u}=f(\bold{Z})\) 을 가지는지를 기반으로 함수를 추정한다. 함수의 값을 계산해야 하는 점의 개수 \(m\)이 학습 데이터 개수보다 훨씬 적기 때문에 Sparse GP라는 이름이 붙은 것이다. 관련 논문의 링크이다.
\(\bm{y}\)에 직접 조건을 걸기보다는 데이터의 특성을 잘 나타낼 수 있는 inducing distribution \(q(\bm{u})\)를 정의하고 이를 활용한다. \(q\)를 어떻게 정의하는지에 대한 연구는 따로 이루어져 있으나, 이와 상관없이 \(\bm{u}\sim q(\bm{u})\)라고 일 때 어떻게 Sparse GP 샘플링이 이루어지는지 살펴보자.
사후분포를 다음과 같이 근사한다.
\[p(\bm{f}_*\mid\bm{y})\approx\int_{\mathbb{R}^m}p(\bm{f_*}\mid\bm{u})q(\bm{u})d\bm{u}\]이 때 \(\bm{u}\sim\mathcal{N}(\bm{\mu_{u}},\bold{\Sigma}_\bm{u})\)이라면 위의 적분을 해석적으로 수행할 수 있으며, 가우시안 평균/공분산 함수를 얻을 수 있다. 식은 다음과 같다.
\[\bm{m}_{*\mid m}=\bold{K}_{*,m}\bold{K}^{-1}_{m,m}\bm{\mu}_{m}\] \[\bold{K}_{*,*\mid m}=\bold{K}_{*,*}+\bold{K}_{*,m}\bold{K}^{-1}_{m,m}(\bold{\Sigma}_\bm{u}-\bold{K}_{m,m})\bold{K}^{-1}_{m,m}\bold{K}_{m,*}\]사용하는 데이터의 수가 적기 때문에 트레이닝은 \(\mathcal{O}(\tilde{n}m^2)\)의 시간 복잡도를 가지고 있다. (\(\tilde{n}\lt n\)은 알고리즘마다 다른 배치 사이즈이다) 이전의 \(\mathcal{O}(n^3)\) 보다 훨씬 개선된 것이다. 하지만 이는 학습시간의 복잡도를 개선시킨 것이지, 샘플링의 복잡도를 개선한 것은 아니다. 샘플링의 복잡도는 위에서 진행한 나이브한 방식과 똑같다.
Function-space approximation은 학습은 효율적이지만 샘플링이 비효율적이다.
Weight-space approximations to GPs
GP를 접근하는 다른 시각에서는 함수 \(f\)를 기저함수의 가중합으로 생각한다. 즉, 커널 \(k\)가 피쳐맵 \(\varphi:\mathcal{X}\rightarrow\mathcal{H}\) 을 가지고 있는 RKHS (Reproducing Kernel Hilbert Space)를 정의한다고 볼 수 있는 것이다. \(\mathcal{H}\)가 separable하다면 커널 \(k\)가 정의하는 내적을 아래와 같이 근사할 수 있는것이다. 아래의 \(\bm{\phi}\)는 유한차원 피쳐맵 \(\bm{\phi}:\mathcal{X}\rightarrow\mathbb{R}^l\)이다.
\[k(\bm{x},\bm{x}')=\langle\varphi(\bm{x}),\varphi(\bm{x}')\rangle_{\mathcal{H}}\approx\bm{\phi}(\bm{x})^\top\bm{\phi}(\bm{x})\]정상성을 가진 공분산 함수에 대해서는 유한차원 피쳐맵은 random Fourier features로 만들어질 수 있다. Bochner Theorem에 따르면 stationary kernel과 spectral density는 Fourier dual이기 때문이다. 추가 설명은 이 링크에 있다. 이것을 샘플링에 이용한다.
\(\bm{\theta}_i\)를 spectral density에 비례하게 샘플링하고 \(\tau_j\sim U(0,2\pi)\)로 샘플링하여 \(\phi_i(\bm{x})=\sqrt{\frac{2}{l}}cos(\bm{\theta}_i^\top\bm{x}+\tau_i)\)를 만든다. 이제 Bayesian Linear Model을 아래와 같이 정의함으로서 \(l\)차원의 GP approximation을 만들게 된다.
\[f(\cdot)=\sum^{l}_{i=1}w_i\phi_i(\cdot),\qquad w_i\sim\mathcal{N}(0,1)\]이제 \(f\)는 marginally Gaussian인 랜덤 함수가 되었고, \(w\)의 분포에 따라서 \(f\)의 분포의 모양 또한 정해지는 것이다. \(w\)의 사후분포 또한 가우시안이 되는데, \(\bm{w}\mid\bm{y}\sim\mathcal{N}(\bm{\mu}_{\bm{w}\mid n},\Sigma_{\bm{w}\mid n})\)라고 한다면 적률은
\[\bm{\mu}_{\bm{w}\mid n}=(\bold{\Phi}^\top\bold{\Phi}+\sigma^2\bold{I})^{-1}\bold{\Phi}^\top\bm{y}\] \[\Sigma_{\bm{w}\mid n}=(\bold{\Phi}^\top\bold{\Phi}+\sigma^2\bold{I})^{-1}\sigma^2\]여기서 \(\bold{\Phi}=\phi(\bold{X})\)는 \(n\times l\) 피쳐 행렬이다. 어쨌든 위의 적률을 구하기 위해 Woodbury matrix identity를 사용하면 \(\mathcal{O}(min\{l,n\}^3)\) 의 복잡도가 필요하다. \(\Sigma^{1/2}_{\bm{w}\mid n}\)을 \(\mathcal{O}(l^3)\)이나 들여가며 계산해야 했던 것보다 더 휴욜적인 것이다. 또한, 이 방법은 basis를 샘플링하는 것이기 때문에 특정 포인트에서의 예측 결과를 얻는 것이 아니라 실제 함수를 얻는 방법이다. 한번 함수를 샘플링 한 후에는 임의의 테스트 포인트에 대해서 추가적인 샘플링 연산이 필요하지 않다는 말이다.
하지만 효율적인 만큼 성능이 마냥 좋지많은 않은데, Fourier basis function을 사용하는 것은 stationary GP일 경우에는 상당히 좋지만 그렇지 않을 경우 성능이 확연히 떨어지는 것이다. 일반적으로 stationary라고 부르기 힘든 GP사후분포에 대해서는 variance starvation이라는 현상에 의해 학습 \(n\)이 증가할수록 외삽 예측이 ill-behaving이 된다.
Break
위에서 설명한 두 non-naive방식을 정리해보자. Function-space approximation을 기반으로 한 sparse GP방법을 사용할 경우 학습 데이터의 양 \(n=\mid\bm{X}\mid\)에 대해서는 효율적이지만 테스트 포인트의 개수 \(*=\mid\bm{X_*}\mid\)에 대해서는 비효율적으로 스케일된다. 거꾸로, Weight-space approximation을 기반으로 한 Fourier features방법을 사용할 경우 \(*\)에 대해서는 잘 스케일하지만 학습 데이터 개수 \(n\)이 증가하면 예측오차가 커지게 된다. 이 논문은 위 두 방법을 효과적으로 섞는 방법을 제안한다.
Proposed Sampling Method
Matheron’s Rule
\(\bm{a}\)와 \(\bm{b}\)가 조인트 가우시안 확률분포이면, 양변에 평균과 공분산을 계산하는 것으로 아래의 등식이 참임을 보일 수 있다.
\[(\bm{a}\mid\bm{b}=\bm{\beta}) \overset{d}{=}\bm{a}+Cov(\bm{a},\bm{b})Cov(\bm{b},\bm{b})^{-1}(\bm{\beta}-\bm{b})\]즉, Matheron’s Rule이 말하고자 하는 것은 조건부 확률변수 \(\bm{a}\mid\bm{b}\)은 사전분포 \(p(\bm{a},\bm{b})\)를 나타내는 항과 \(\bm{b}=\bm{\beta}\)를 관찰함으로서 생기는 사전분포에 대한 오차를 나타내는 항으로 나누어질 수 있다는 것이다. 다른말로 하자면 \(\bm{a}\mid\bm{b}\)를 샘플링하기 위해서는 사전분포에서 \(\bm{a}\)와 \(\bm{b}\)를 동시에 샘플한 후에 위의 식과 같이 \(\bm{\beta}-\bm{b}\)의 잔차를 \(\bm{a}\)에 업데이트 해주는 방식으로 진행할 수 있는 것이다. 이를 GP에 적용하자면,
\(f\sim\mathcal{GP}(0,k)\)이고 marginal \(\bm{f}_m=f(\bm{Z})\)일 때 \(\bm{f}_m=\bm{u}\)에 조건부 과정은 in distribution으로 아래를 만족한다.
\[(f\mid\bm{u})(\cdot)\overset{d}{=}f(\cdot)+k(\cdot,\bold{Z})\bold{K}^{-1}_{m,m}(\bm{u}-\bm{f}_m)\]Matheron’s Rule에서 설명한 것과 같이 사후분포=사전분포+업데이트 형식인 것이다. 이런 식으로 함수를 샘플링 하는 것을 pathwise update라고 한다. 사후분포를 sample path별로 업데이트 하는 것이기 때문에 사후 공분산 행렬을 explicitly 구할 필요가 없고, 이것이 효율적인 샘플링의 주요한 요소가 된다.
Pathwise updates in sampling methods
위에서 본 세가지 샘플링 방식을 Pathwise update방식으로 나타내면 아래와 같다.
Exact GP: \(\bm{f}_*\mid\bm{y}\overset{d}{=}\bm{f}_*+\bold{K}_{*,n}(\bold{K}_{n,n}+\sigma^2\bold{I})^{-1}(\bm{y}-\bm{g}-\epsilon)\)
Sparse GP: \(\bm{f}_*\mid\bm{u}\overset{d}{=}\bm{f}_*+\bold{K}_{*,m}\bold{K}_{m,m}^{-1}(\bm{u}-\bm{f}_m)\)
Weight-space GP: \(\bm{w}\mid\bm{y}\overset{d}{=}\bm{w}+\bold{\Phi}^\top(\bold{\Phi}\bold{\Phi}^\top+\sigma^2\bold{I})^{-1}(\bm{y}-\bold{\Phi}\bm{w}-\epsilon)\)
Exact GP의 경우 \(\bm{f}_*\)와 \(\bm{f}\)를 사전분포에서 샘플링한 후 노이즈 \(\epsilon\sim\mathcal{N}(\bm{0},\sigma^2\bold{I})\)와 \(\bm{f}\)를 결합하여 \(\bm{y}\)의 사전분포에서 \(\bm{f}+\epsilon\)이 샘플링되도록 진행되고, Sparse GP의 경우 \(\bm{f}_*\)와 \(\bm{f}_m\)을 사전분포에서 샘플링 한 후 \(\bm{u}\sim q(\bm{u})\)를 따로 샘플링한다. Weight-space GP는 초기 weight vector \(\bm{w}\sim\mathcal{N}(0,\bold{I})\)의 업데이트를 함으로서 진행된다.
위와 같이 Pathwise update방식으로 샘플링을 진행하는 것 자체는 그렇게 효율적이지는 않지만, 각 방법의 비효율이 어느 항에서 기인하는지 알 수 있다. Sparse GP의 경우에는 \(\mathcal{O}(*^3)\)이 사전분포에서 발생하는 것을 볼 수 있다. 오히려 업데이트 부분은 \(*\)에 대해서 선형이다. Weight-space Gp에서는 부정확성이 업데이트항에서 발생하는 것을 알 수 있다. stationary 사전분포는 괜찮지만 그렇지 않은 학습 데이터의 부정확한 표현 때문이다.
Pathwise updates with decoupled bases
각 샘플링 방법이 가지는 장점만을 섞으면 더 효율적인 샘플링 방법이 탄생한다. 사전분포에 해당하는 항은 Fourier basis \(\phi_i(\cdot)\)를 기반으로 한 weight-space 방법을 쓰고, 업데이트에 해당하는 항은 inducing location과 kernel basis \(k(\cdot,\bm{z}_j)\) 를 기반으로 한 function-space 방법을 쓰는 것이다. 아래와 같은 sampling 방법을 Decoupled Sparse DP Approximation, 혹은 DSGP라고 부르기로 한다.
\[(f\mid\bm{u})(\cdot)\overset{d}{\approx}\sum^l_{i=1}w_i\phi_i(\cdot)+\sum^m_{j=1}v_jk(\cdot,\bm{z}_j)\]\(\bm{v}=\bold{K}^{-1}_{m,m}(\bm{u}-\bold{\Phi}\bm{w})\)이다. 이 표현에서 exact GP로 넘어가기 위해서는 \(\bold{\Phi}\bm{w}\)에다가 노이즈 \(\epsilon\sim\mathcal{N}(0,\sigma^2\bold{I})\)를 더하고, \(\bold{Z},\bm{u},\bold{K}^{-1}_{m,m}\)을 \(\bm{X,y,}(\bold{K}_{n,n}+\sigma^2\bold{I})^{-1}\)로 바꾸면 된다.
다시 정리하자면, \(k\)가 stationary하다는 가정이 있기 때문에, \(\bm{w}\)가 정규선형분포를 가지는 \(l\)차 베이지안 선형모델 \(f(\cdot)=\bm{\phi}(\cdot)^\top\bm{w}\)를 사용하는 것이 사전분포를 잘 나타내는 방법이라고 할 수 있다. 또한, kernel basis \(k(\cdot,\bm{z}_j)\)가 inducing locations \(\bm{z}_j\in\bold{Z}\)와 일대일 관계에 있기 때문에 업데이트 부분을 잘 나타낼 수 있다.
단계별로 알아보면, (i) \(f\)를 weight-space prior를 통해 샘플링하고, (ii) \(\bm{u}\sim q(\bm{u})\)를 통해 얻은 샘플로 \(\bm{u}-f(\bm{Z})\) 잔차를 계산해 업데이트 부분을 구한다. 마지막으로는 (iii) 그 두개를 더하여 정의역 \(\mathcal{X}\)전반에 대해서 사후함수를 얻을 수 있게 되는 것이다. 해당 단계가 아래의 사진에 나와있다. 왼쪽이 prior, 중간이 update, 오른쪽이 posterior이다.
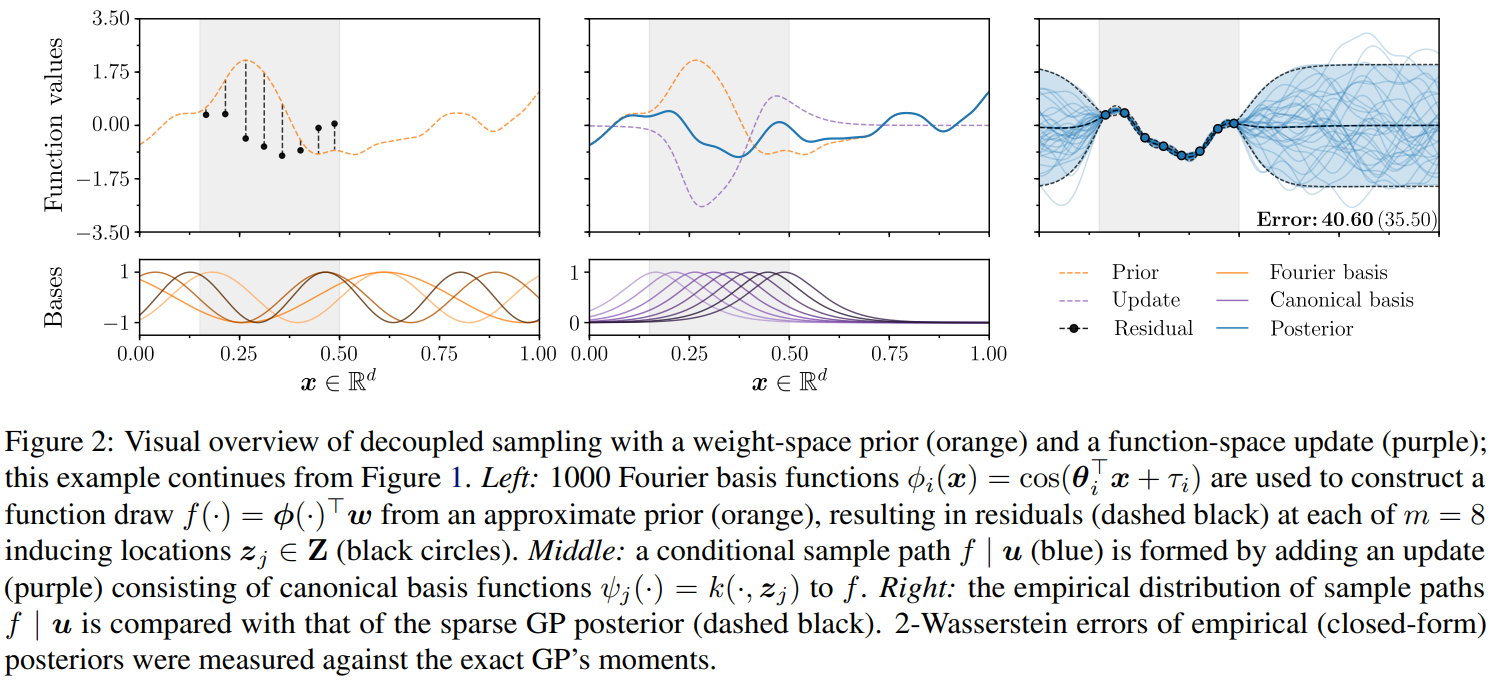
직관적으로 생각하면 업데이트 항이 \(\bm{u}-f(\bold{Z})\)만큼 ‘correcting’한다는 의미는 사후분포의 평균의 의미를 포함하는 것이다. 사전분포 \(f\) 대신에 사전분포의 기댓값 \(\mathbb{E}[f]\)를 생각한다면 DSGP가 \(\mathbb{E}[f\mid\bm{u}]\)가 되는 것이다. 업데이트항은 커널 basis로 나타내어지기 때문에 기댓값을 취한다면 Sparse GP의 posterior의 기댓값과 일치하게 되는 것이다. 즉, DSGP에서는 학습 데이터 (혹은 inducing points)가 늘어남에 따라서 well-behaving이 되고 불확실성도 낮아지는 것이다. 거꾸로 생각하면 데이터를 제거할수록 prior에 가까워지는 것이다.
복잡도를 살펴보면 테스트 데이터 \(\bold{X}_*\)에 따라서 선형적으로 스케일되기 때문에 훨씬 효율적으로 샘플링할 수 있다. 또한, \(\bm{x}\)에 대해서 pathwise differentiable하기 때문에 GP의 극값을 생각하는 데에도 도움이 많이 된다.
Error bounds
샘플링 수식의 해석적 특징을 살펴봄으로써 DSGP의 사전분포의 퀄리티를 평가한다. GP들 사이의 2-Wasserstein distance를 계산하는데, 몬테카를로 세팅에서 유용한 평가지표가 된다. Wasserstein distance가 Lipschitz 연속인 함수와 그 근사치 사이의 오차에 대한 상한을 제시해 주기 때문이다. 또한, exact GP와 유한차원 근사치 사이의 2-Wasserstein distance는 유한이기 때문에 평가 비교에도 유용한 것이다. 다음과 같은 proposition이 성립힌다.
Proposition 1. \(\mathcal{X}\subseteq\mathbb{R}^d\)가 컴펙트하고 stationary kernel \(k\)가 \(f\sim\mathcal{G}(0,k)\)가 almost surely 연속일 수 있게 regular하다고 가정하자. 또한, \(f\mid\bm{y}\)는 \(f\)의 사후분포라고 하고, \(f^{(s)}\)와 \(f^{(d)}\)는 각각 sparse GP 랑 DSGP에 해당하는 함수라고 하자. DSGP의 사전분포의 근사치는 \(f^{(w)}\)라고 하자. \(W_{w,L^2(\mathcal{X})}\)와 \(W_{2,C(\mathcal{X})}\)는 각각 \(L^2(\mathcal{X})\)와 supremum norm을 가지는 연속 함수 공간 \(C(\mathcal{X})\)에서의 2-Wasserstein distance이라고 할 때,
\[W_{2,L^2(\mathcal{X})}(f^{(d)},f\mid\bm{y})\leq \newline W_{2,L^2(\mathcal{X})}(f^{(s)},f\mid\bm{y})+C_1W_{2,C(\mathcal{X})}(f^{(w)},f)\]위 부등식을 살펴보면 DSGP 샘플의 오차는 DSGP를 이루는 두개의 항의 오차로 깔끔히 분리되는 것을 볼 수 있다. 첫번째 항은 sparse posterior의 오차이고 두번째 항은 error in the prior이다. 특히, error in the prior는 inducing distribution \(q(\bm{u})\)이 아닌 inducing locations \(\bold{Z}\)을 통해서 posterior로 전이된다.
다음으로는 DSGP의 적률을 살펴본다. DSGP의 기대값이 sparse GP의 기대값과 같기 때문에 sparse GP의 오차가 posterior 공분산에 미치는 영향에 대해서 살펴본다. prior를 근사하기 위해 random Fourier function을 사용하는데, 이 오차는 \(l\)차항의 basis \(\phi\)에 의해 결정된다. \(\phi\)는 \(\tau\sim U(0,2\pi)\)와 \(\bm{\theta}\sim s(\bm{\theta})\)에 의해 주어진다.(\(s(\cdot)\)은 \(k\)의 normalised spectral density를 나타낸다.)
Proposition 2 앞선 Proposition에 이어서, \(k^{(f\mid\bm{y})},k^{(w)},k^{(s)},k^{(d)}\)가 각각 \(f\mid\bm{y},f^{(w)},f^{(s)},f^{(d)}\)의 공분산함수라고 하고, 연속 함수의 supremum norm을 \(\lVert\cdot\rVert_{C(\mathcal{X^2})}\)이라고 하고, \(C_2\)와 \(C_3\)를 상수라고 한다면 아래가 성립한다. \(C_3=m[1+\lVert\bold{K}^{-1}_{m,m}\rVert_{C(\mathcal{X}^2)}\lVert k\rVert_{C(\mathcal{X}^2)}]^2\)이고 \(C_2\)는 Sutherland and Schneider (2015)에 나온다.
\[\mathbb{E}_\phi\lVert k^{(d)}-k^{(f\mid\bm{y})}\rVert_{C(\mathcal{X^2})}\newline\leq\lVert k^{(s)}-k^{(f\mid\bm{y})}\rVert_{C(\mathcal{X^2})}+\frac{C_2C_3}{\sqrt{l}}\]DSGP와 마찬가지로, posterior 사후분포의 공분산함수는 sparse GP의 공분산함수 \(k^{(s)}\)와 prior의 근사치의 공분산함수 \(k^{(w)}\)에 관련된 항으로 나누어질 수 있다. Prior의 근사치에서 발생된 오차는 RFF를 사용하기 때문에 나타나는 오차이며, basis function의 수 \(l\)이 증가하는 것과는 무관한 속도로 decay한다. 공분산함수를 몬테카를로 근사할 때 RFF의 성격을 반영한다고 볼 수 있다. 실제로는 학습 데이터 개수 \(n\)이 데이터의 차원 \(d\)보다 더 빠르게 증가하는데, RFF방법만 사용한다면 variance starvation이 있어 별로 이득이 없지만 DSGP는 variance starvation 현상이 없어서 차원에 상관없는 수렴속도가 확실히 장점으로 작용하는 것이다.
My Conclusion
실험을 몇 개 한 결과도 있었지만 잘 나왔겠지. 개인적으로 Rasmussen & Williams를 보면서 GP 공부를 하고 있었는데 최근에 ICML에 논문이 나와서 바로 읽어봤다. GP는 역사가 오래된 것 같은데 최근까지도 꾸준히 관심을 받는 모델같다. 굉장히 로컬리 근사하면서도 분포에 대한 가정을 잃지 않는 모델인 것 같아서 재밌는거같다. 이론대로 샘플링을 시도하는 건 상당히 비효율적이기 때문에 실생활에 쓰이려면 이 논문과 같은 샘플링 기법을 새로 개발해야 한다는 것도 매력적이다. 역시 이론은 쓸모없어야 제맛이지!
Leave a comment