[Paper Review] Addressing Function Approximation Error in Actor-Critic Methods
Arxiv 링크
TD3 논문. 가치기반 강화학습 알고리즘에서 overestimation bias가 발생하는 현상은 널리 알려진 사실이며 많은 연구가 진행된 부분이다. 이 overestimation bias는 가치함수를 근사하는 함수근사 방법에서 발생하는 오차가 중첩된다는 점과 TD-Learning을 통해 진행되는 bootstrapping이 주 원인이다. 이 논문에서는 Actor-Critic 기법에서도 가치기반 기법에서 나타나는 overestimation bias가 똑같이 나타나는 것을 발견하여 이를 해결하고 분산을 줄이고자 한다. DPG에서 일어나는 overestimation bias를 기반으로 DPG 알고리즘을 개선하는 방안을 제안한다.
Introduction
가치기반 기법의 일종인 Q-Learning을 생각해보자. Tabular setting에서 Q-Learning은 Q값을 추정하는 데에 미래 Q값의 최댓값을 사용한다. 근데 Q값이라는 것 자체가 approximation이기 때문에 부정확하고, 부정확한 값의 최댓값을 사용하는 것은 가장 큰 노이즈를 채택하는 것과 같다. 계속해서 overestimation이 생기는 것이다. 게다가 Q값을 추정하기 위해 이전 단계에서 추정한 Q값을 사용하는 bootstrapping이 진행된다. 추정치를 사용하여 추정하기 때문에 에러가 계속해서 쌓인다.
이 논문은 강화학습 알고리즘, 특히 actor-critic기법에서 발생하는 overestimation bias와 high variance문제를 해결하기 위해 TD3 (Twin Delayed Deep Deterministic) policy gradient algorithm을 제안한다.
Background
먼저 Actor-Critic을 복습할 것이다. 이를 위해 강화학습의 목적을 생각하자. 아래 목적 함수 (기대 보상) 를 최대화시키는 정책 \(\pi_\phi\)를 찾는 것이 목적이다. \(\phi\)는 정책의 파라미터이다.
\[J(\phi)=\mathbb{E}_{s_i\sim p_\pi,a_i\sim\pi}[R_0]\]Actor-critic 기법에서는 정책을 찾기 위해 \(J(\phi)\)를 증가시키는 방향으로 \(\phi\)를 바꾸어간다. Deterministic action을 가정했을 때, \(\nabla_\phi J(\phi)\)는 아래와 같이 나타낼 수 있다. (DPG논문에서 보인 Deterministic Policy Gradient)
\[\nabla_\phi J(\phi)=\mathbb{E}_{s\sim p_\pi}[\nabla_\phi\pi_\phi(s)\nabla_aQ^\pi(s,a)\mid _{a=\pi(s)}]\]\(Q^\pi(s,a)=\mathbb{E}_{s\sim p_\pi,a_i\sim\pi}[R^t\mid s,a]\)는 상태 \(s\)에서 행동 \(a\)를 택한 후 정책 \(\pi\)를 따라갔을 때의 기대 보상이다. Actor는 \(\nabla_\phi J(\phi)\)의 방향으로 정책을 업데이트 하고, Critic은 \(Q^\pi\)를 업데이트 한다.
Overestimation Bias
Discrete action 상황에서 Q-Learning을 생각해보면 Q값을 추정하는데 쓰이는 타겟은 \(y=r+\gamma\,\underset{a'}{\text{max}}\,Q(s',a')\)으로 나타낼 수 있다. \(Q\)값에 에러 \(\epsilon\)이 있다고 생각하면 타겟에도 그 에러가 전달이 되는데, 에러가 들어간 \(Q\)값의 최댓값을 생각해보면 에러가 없는 \(Q\)값의 최댓값에 비해 크다는 것을 알 수 있다. 즉, \(\mathbb{E}_\epsilon[\underset{a'}{\text{max}}(Q(s',a')+\epsilon)]\geq\underset{a'}{\text{max}}\,Q(s',a')\)인 것이다. \(\epsilon\)의 기댓값이 0이어도 \(\text{max}\)를 취하기 때문에 에러가 계속해서 쌓이게 된다. 여기까지가 지금까지 충분히 연구된 Q-Learning에서의 overestimation bias이다. 이 논문에서는 이 아이디어를 actor-critic으로 확장한다.
Overestimation Bias in Actor-Critic
Actor-Critic기법에서 정책은 Actor가 Policy Gradient에 따라서 정책의 파라미터를 조정하면서 찾아진다. 정책 \(\pi\)와 그 파라미터 \(\phi\)가 있을 때, 이 파라미터가 어떻게 업데이트 되는지에 따라서 \(\phi_{\text{approx}}\)과 \(\phi_{\text{true}}\)를 정의할 것이다. 먼저 \(\phi_{\text{approx}}\)은 Policy Gradient에 사용되는 \(Q\)함수로 \(\text{max}\)를 통해 추정한 \(Q_\theta\)을 사용한 파라미터라고 정의한다. 반대로 \(\phi_{\text{true}}\)는 ‘true value function’인 \(Q^\pi\)를 통해서 업데이트 된 파라미터라고 정의한다. \(Q^\pi\)는 우리가 실제로 알 수 없는 이론적인 값을 말한다. 아래와 같이 쓸 수 있다.
\[\phi_{\text{approx}}=\phi+\frac{\alpha}{Z_1}\mathbb{E}_{s\sim p_\pi}[\nabla_\phi\pi_\phi(s)\nabla_aQ_\theta(s,a)\mid_{a=\pi_\phi(s)}]\] \[\phi_{\text{true}}=\phi+\frac{\alpha}{Z_2}\mathbb{E}_{s\sim p_\pi}[\nabla_\phi\pi_\phi(s)\nabla_aQ^\pi(s,a)\mid_{a=\pi_\phi(s)}]\]두 파라미터의 다른 점은 어떠한 \(Q\)값을 사용하느냐 (우리가 추정한 값인지 실제 값인지)와 learning rate을 normalize해주는 \(Z\)값 뿐이다. \(Z\)는 \(Z^{-1}\lVert\mathbb{E}[\cdot]\rVert=1\)이 되게 설정한 인위적인 값이다. \(Z\)가 없는 일반적인 케이스에도 아래의 내용이 성립하나 좀 더 간단한 논리 전개를 위해 \(Z\)를 활용한다. 또한, 어떠한 \(\phi\)업데이트를 사용하냐에 따라 업데이트된 파라미터를 사용하는 정책을 \(\pi_{\text{approx}}\)와 \(\pi_{\text{true}}\)라고 하자.
먼저, \(\pi_{\text{approx}}\)와 \(\pi_{\text{true}}\)의 추정 value 값, 즉 \(Q_\theta(s,\pi_{\text{approx}})\)와 \(Q_\theta(s,\pi_{\text{true}})\)를 생각해보자. \(\phi_{\text{approx}}\)는 \(Q_\theta\)를 최대화하는 방향으로 업데이트 되기 때문에 업데이트하는 스텝 사이즈를 충분히 작게 한다면 \(\phi_{\text{true}}\)를 사용한 것보다 \(\phi_{\text{approx}}\)를 사용한 정책의 추정치를 더 높게 할 수 있음을 알 수 있다. \(\phi_{\text{true}}\)는 \(Q_\theta\)가 아니라 \(Q^\pi\)를 최대화 하는 방향으로 업데이트된 값이기 때문이다. 즉,
\[\exist\epsilon_1:\alpha\le\epsilon_1\Rightarrow \mathbb{E}[Q_\theta(s,\pi_{\text{approx}}(s))]\ge\mathbb{E}[Q_\theta(s,\pi_{\text{true}}(s))]\]비슷하게 \(\pi_{\text{approx}}\)와 \(\pi_{\text{true}}\)의 실제 value 값, 즉 \(Q^\pi(s,\pi_{\text{approx}})\)와 \(Q^\pi(s,\pi_{\text{true}})\)를 생각하면 반대의 표현을 얻을 수 있다.
\[\exist\epsilon_2:\alpha\le\epsilon_2\Rightarrow \mathbb{E}[Q^\pi(s,\pi_{\text{true}}(s))]\ge\mathbb{E}[Q^\pi(s,\pi_{\text{approx}}(s))]\]이제 가치기반 기법에서 overestimation bias를 생각하면 \(\pi_{\text{true}}\)의 실제 value와 추정 value 사이의 대소관계를 알 수 있다. \(\mathbb{E}[Q_\theta(s,\pi_{\text{true}}(s))]\ge\mathbb{E}[Q^\pi(s,\pi_{\text{true}}(s))]\) 이라고 한다면, 이제 \(\alpha\)를 위의 \(\epsilon_1\)이나 \(\epsilon_2\)보다 작게 잡으면 새로운 부등식을 얻는다.
\[\exist\epsilon_1,\epsilon_2:\alpha\le\text{min}(\epsilon_1,\epsilon_2)\Rightarrow \\ \mathbb{E}[Q_\theta(s,\pi_{\text{approx}}(s))]\ge\mathbb{E}[Q^\pi(s,\pi_{\text{approx}}(s))]\]Actor-Critic에서의 overestimation bias이다! Iteration을 거듭하면 위 에러가 critic에 계속해서 쌓이게 되고, 그 critic에 기반하여 정책을 만드는 actor 또한 최적이 아닌 정책을 만들게 된다. 이게 반복되면 피드백 루프가 생기는데, suboptimal action이 suboptimal critic에 의해서 고평가받게 되고, 다음 정책이 해당 suboptimal action을 선택하는 방향으로 업데이트되는 결론이 나오기 때문에 계속해서 안좋은 방향으로 나아가는 것이다.
Clipped Double Q-Learning for Actor-Critic
과대평가보다는 과소평가가 낫다. \(Q\)함수 2개를 사용해서 작은 놈을 사용하자.
지금까지 overestimation bias를 해결하기 위한 방법이 많이 제시되었으나 actor-critic setting에서는 별로 쓸모가 없었고, 해당 논문은 Double Q-Learning에서 제안한 방법을 조금 변형해서 모든 actor-critic 기법에서 critic에 가할 수 있는 방안을 새로 제안한다.
기본적으로 가치기반 기법에서 overestimation이 이루어지는 이유는 action을 선택하는 데에 쓰이는 함수와 그 action을 사용하여 value를 추정하는 함수가 같기 때문이다. 같은 함수는 같은 오차를 가지고 있기 때문에 중첩이 일어나는 것이다. 이 말은 \(\text{max}\,Q(s,a)\)의 \(a\)를 선택 (greedy update)하는 부분에 쓰이는 \(Q\)함수와 value를 평가하는데 쓰이는 \(Q\)함수를 분리하면 overestimation 현상이 완화될 수 있다는 것이다. Levine의 강의자료를 참고하면 아래와 같다.
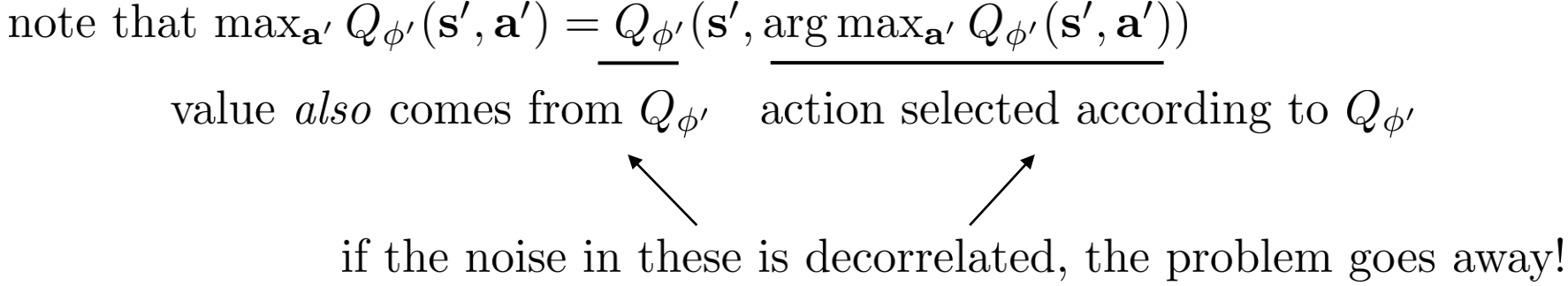
Double DQN에서는 (Double Q-Learning 이후에 나온 논문이다. 헷갈리지 말자.) 평가에 타겟 네트워크를 사용하였고 선택에 현재 네트워크를 사용하였다. 타겟 네트워크는 일정 스텝마다 현재 네트워크를 복사하여 freeze한 것임을 생각하면, 타겟과 현재 네트워크 간의 관계가 없다고 할 수는 없지만 이정도로만 분리해도 overestimation bias가 잡히는 모습을 볼 수 있다. (타겟에 대해서는 다음 부분에서 다룬다. 굳이 선택과 평가에 쓰이는 \(Q\)를 현재와 타겟 네트워크로 둘 필요는 없다. 그저 타겟 네트워크가 필요해서 만들어놓고 보니까 \(Q\)가 두개 생겨서 그 두개를 쓰는 것일뿐.)
Actor-Critic에서도 이와 같이 평가와 선택을 분리한다. Critic을 학습하기 위한 타겟을 만들 때 타겟 정책이 아닌 현재 정책 (\(\pi_\phi\)) 을 사용하는 것이다. 아래와 같다.
\[y=r+\gamma Q_{\theta'}(s',\pi_\phi(s'))\]하지만 실제로 actor-critic에서 정책이 빠르게 업데이트 되지 않으면 타켓 네트워크와 현재 네트워크가 너무 비슷하여 각각의 함수를 따로 두어 추정치를 계산하는 것에 큰 메리트가 없다. 그렇기 때문에 Double Q-Learning에서 처음에 제안되었던 아래 식을 사용한다.
\[y_1=r+\gamma Q_{\theta'_2}(s',\pi_{\phi_1}(s'))\\ y_2=r+\gamma Q_{\theta'_1}(s',\pi_{\phi_2}(s'))\]\(y_1\)은 \(Q_{\theta_1}\)를 업데이트 할 때 쓰이는 타겟인데, \(y_1\)을 표현하는 식 안에 \(Q_{\theta'_2}\)가 들어있는 것을 볼 수 있다. \(Q_{\theta'_2}\)는 \(Q_{\theta_2}\)를 주기적으로 복사하거나 \(\theta_2\)를 이동평균적으로 업데이트 하여 만들어지는데, 사실 이 값이 \(Q_{\theta_1}\)에 완벽히 독립적이라고 하기는 힘들다. \(Q_{\theta_2}\)를 업데이트 하는 데에도 \(Q_{\theta_1}\)의 값이 영향을 미치고, 결국 같은 replay buffer 데이터셋을 활용하여 학습되기 때문이다. 따라서, 만약 어떤 상태 \(s\)에 대해서 안그래도 overestimation bias가 있는 \(Q_{\theta_1}\)보다 더 큰 값의 \(Q_{\theta_2}\)가 사용된다면 정책을 정확히 평가할 수 없다. \(Q_{\theta_2}(s,\pi_{\phi_1}(s))\gt Q_{\theta_1}(s,\pi_{\phi_1}(s))\)일 때 \(Q_{\theta_2}\)가 사용되는 경우를 말하는 것이다.
이 문제를 해결하기 위해 타겟을 취할 때 \(Q_{\theta_1}\)과 \(Q_{\theta_2}\) 둘 중 작은 것을 사용하는 방법을 취한다. Clipped Double Q-Learning이라고 명명한 이 방법은 아래와 같이 표현할 수 있다.
\[y_1=r+\gamma\,\underset{i=1,2}{\text{min}}\,Q_{\theta'_{i}}(s',\pi_{\phi_1}(s'))\]따로 학습된 \(Q\)함수의 최솟값을 취하는 과정에서 underestimation bias가 생길 수는 있으나 overestimation bias보다는 훨씬 낫기 때문에 이 방법을 사용한다. (overestimation bias와는 다르게 underestimation bias는 iteration이 진행될 때 에러가 전파되지는 않는다. 정책은 높은 value만 택하기 때문이다.)
실제로 구현할 때 \(y_1=y_2\)라고 놓으면 정책을 하나만 (\(Q_{\theta_1}\)에 대해서) 학습해도 된다. 만약 \(Q_{\theta_2}\lt Q_{\theta_1}\)이면 Double DQN과 같은 꼴이 되어서 overestimation bias가 완화되고, \(Q_{\theta_2}\lt Q_{\theta_1}\)인 상황이면 \(Q_{\theta_1}\)을 추정하는 데 \(Q_{\theta_2}\)의 정보가 쓰여서 Double Q-Learning에서 설명하는 상황이 되어 overestimation bias가 완화된다.
Clipped Double Q-Learning을 사용하면 또 하나의 장점이 있는데, 바로 분산이 줄어든다는 것이다. 계속해서 말하는 function approximation error를 하나의 확률변수로 보았을 때, 확률변수의 분산이 증가할수록 확률 변수 집합의 최솟값의 기댓값이 줄어드는 성질을 생각해보자. Error의 분산이 클수록 최솟값이 작아져서 결국에는 정책의 선택을 못받게 된다. 즉, \(\text{min}\) operator가 있기 때문에 \(Q\)함수는 error의 분산이 적은 value 추정치를 가지는 state를 더 선호하게 될 것이다.
Addressing Variance
분산을 통해 만들어진 overestimation bias를 줄이는 것 이외에도 분산 자체를 줄이는 시도를 했다. 분산이 큰 추정치는 그래디언트를 업데이트 하는 데 노이즈를 주어서 학습을 방해한다. 이 부분에서는 각 update iteration마다 발생하는 에러를 줄이는 것의 중요성과 타겟 네트워크-에러 간의 관계를 다룬다. 나아가 분산을 줄일 수 있는 Actor-Critic 알고리즘을 제안한다.
Accumulating Error
TD-Learning은 bootstrapping을 사용하기 때문에 에러가 중첩되는 문제점이 있다. 추정치를 사용해서 추청하기 때문이다. 각 단계에서 발생하는 에러가 작더라도 반복되면 상당히 큰 에러가 되기 때문에 큰 문제가 될 수 있다. 뿐만 아니라, 추정치 자체를 함수 근사 방법으로 추정하기 때문에 에러가 더 심각해진다. 함수 근사 방법을 사용하면 Bellman equation을 완벽히 만족하지 못하고 residual이 항상 남게 된다. 이 residual을 TD-error \(\delta(s,a)\) 라고 부른다.
\[\delta(s,a)=r+\gamma\mathbb{E}[Q_\theta(s',a')]-Q_\theta(s,a)\]\(Q_\theta\)에 대한 식으로 정리해서 하나의 time step을 추가로 전개하면 아래와 같음을 보일 수 있다.
\[Q_\theta(s_t,a_t)=r_t+\gamma\mathbb{E}[Q_\theta(s_{t+1},a_{t+1})]-\delta_t\\ =r_t+\gamma\mathbb{E}[r_{t+1}+\gamma\mathbb{E}[Q_\theta(s_{t+2},a_{t+2})-\delta_{t+1}]]-\delta_t\\ =\mathbb{E}_{s_t\sim p_\pi,a_i\sim\pi}\Big[\sum\limits^{T}_{i=t}\gamma^{i-t}(r_i-\delta_i)\Big]\]Bootstrapping을 사용한다면 value 추정치인 \(Q_\theta\)는 기대 보상을 추정한다기 보다는 기대 보상에서 할일된 미래 TD-error의 기댓값을 뺀 값을 근사하는 것이다. 즉, \(Q_\theta\)의 분산은 기대 보상과 TD-error의 분산에 의해 결정된다. 특히 \(\gamma\)가 큰 경우에는 iteration이 진행될 때마다 분산이 계속 쌓인다. 게다가 미니배치 단위로 그래디언트 업데이트를 하기 때문에 에러가 전체 데이터에서 줄어든다는 보장도 없다. Overestimation 문제를 위에서 어느 정도 해결했다면, 이 부분에서는 TD-error의 분산을 해결하는 법을 살펴보자.
Target Networks and Delayed Policy Updates
Critic이 충분히 정신 차릴때까지 기다렸다가 Actor를 업데이트하자.
앞서 계속 말했던 타겟 네트워크에 대한 설명이다. 타겟 네트워크는 \(Q\)함수 추정을 안정화하는 데 효과적인 방법이다. 가치함수를 근사할 때 쓰이는 뉴럴넷 모델은 함수가 복잡해서 최적화하기가 쉽지 않다. 작은 그래디언트 스텝을 따라서 조금씩 함수값을 줄이는 방향으로 최적화를 진행하는데, 이 때 목적함수가 고정되어 있어도 최적화하기란 상당히 힘들다. 하지만 강화학습에서 매 그래디언트 스텝이 진행될 때마다 목적함수가 바뀐다면 학습이 굉장히 불안해지고 수렴하지 않을 수도 있다. 아래의 식을 최소화할 때를 생각해보자.
\[r+\gamma Q_\theta(s',a')-Q_\theta(s,a)\]위 식을 최소화 하는 목적은 \(Q(s,a)\)를 \(r+\gamma Q_\theta(s',a')\)에 최대한 가깝게 만드는 것이다. \(Q_\theta(s,a)\)부분을 피팅한다고 생각하면 된다. 거리를 좁히고 싶은 두 값 모두에 \(Q_\theta\)라는 같은 함수가 들어가는 것을 알 수 있다. 따라서 그래디언트 스텝을 따라 업데이트를 한번 할 때마다 타겟 함수와 값이 달라진다. 이 문제를 완화하기 위해서 target network를 사용한다. Target network는 위 함수에서 피팅하는 ‘목적’이 되는 \(r+\gamma Q_\theta(s',a')\)에 해당하는 함수가 변하지 않게, 또는 변하더라도 천천히 변하도록 고정하는 기법을 말한다. 목표가 덜 변하는 것이 학습을 안정적으로 만들기 때문이다.
Target network를 만들 때는 주로 이동평균 기법과 copy and freeze 방법이 사용된다. 전자는 그래디언트 스텝이 진행되는 궤도를 따라서 파라미터를 이동평균한 함수를 목적함수로 사용하는 것이고, 후자는 몇 그래디언트 스텝 주기마다 목적함수를 업데이트 하는 것이다. 둘 다 타겟을 안정화한다는 점에서는 맥락이 같다.
만약 이 target network가 없다면 value 추정치의 큰 분산으로 인해 정책 업데이트가 불안정해진다는 단점이 있다. 특히, actor와 critic 사이의 관계를 들여다볼 수 있는데, actor가 만드는 정책의 질이 좋지 않을 때 overestimation으로 인해서 critic의 value 추정치가 발산하게 되고, critic이 만드는 value 추정치가 정확하지 않으면 이를 기반으로 결정을 내리는 actor의 정책이 악화된다.
그렇다면 Actor-Critic에서 target network의 이점을 최대한 활용하는 방법은 무엇일까. Target network를 사용하여 value estimate을 업데이트 하면 매 업데이트 스텝마다 발생하는 에러가 줄어들게 된다는 점을 생각하면 에러가 좀 진정이 될 때 까지는 target network를 고정시킨 상태에서 value estimate을 계산하고 어느정도 value estimate이 학습된 후에는 정책을 업데이트 하는 방식을 생각해 볼 수 있을 것이다. 이 방법이 본 논문이 제안하는 delayed policy update이다.
Target Policy Smoothing Regularization
Action value의 값을 스무딩하자.
Deterministic 정책의 단점은 state당 1개의 action밖에 할당하지 못하기 때문에 action-value estimate의 오차에 민감하게 반응하며 과대평가된 action value에 오버피팅하기 쉽다는 것이다. 따라서 critic이 value estimate을 업데이트 할 때 타겟의 분산이 커지는 결과를 맞게 된다. Regularization을 통해서 이를 해결하고자 한다.
SARSA에서 영감을 받은 이 regularization 방식을 target policy smoothing이라고 부르며, 비슷한 행동은 비슷한 value를 가져야 한다는 게 기본 아이디어이다. \(Q_\theta\)를 \(r+\mathbb{E}_\epsilon[Q_{\theta'}(s',\pi_{\phi'}(s')+\epsilon)]\)에 피팅함으로써 target action 주변 지역에도 피팅되게 하고 value estimate을 스무딩한다. 실제로 구현할 때는 action을 샘플링 할 때 target policy에서 선택한 action에 \(\epsilon\)을 더한 값을 사용해서 미니배치 단위로 평균을 낸다. 수식으로 표현하면 아래와 같다.
\[y = r+\gamma Q_{\theta'}(s',\pi_{\phi'}(s')+\epsilon)\\ \epsilon\sim \text{clip}(\mathcal{N}(0,\sigma),-c,c)\]clip은 c와 -c 사이의 값만을 \(\epsilon\)으로 취한다는 뜻으로, action의 근처라는 것을 보장하기 위해서 사용한다. Expected SARSA의 경우에도 target policy에 노이즈를 추가하여 off-policy 방법으로 value estimate이 계산된다. 이런식으로 추정된 value는 스무딩이 되었기 때문에 더 안전한 행동을 유도한다고 알려져있다.
이제 알고리즘을 정리하면 아래와 같다.

My Conclusion
SAC와 더불어 나름 최신 알고리즘이라고 쓰이는 TD3를 공부했다. 구현은 언제할런지..
Leave a comment