[Paper Review] Reinforcement Learning and Control as Probabilistic Inference: Tutorial and Review
제발 틀린거 있으면 피드백 주세요.
Arxiv 링크
Levine이 쓴 리뷰논문. 강화학습의 제어문제를 확률적 추론 문제로 해결하는 방법을 보여주었다. Soft Q-Learning이나 Soft Actor-Critic 모두 확률적 추론 프레임워크 하에서 아주 자연스럽게 정의되는 알고리즘임을 알 수 있다. Levine이 진행하는 UC Berkeley의 CS285 19강에서도 같은 내용을 다루고 있어서 논문과 해당 학습자료를 참고하여 리뷰글을 작성한다. 기가 맥힌다. 시작.
Introduction
강화학습 문제에서 시스템을 확률 그래프 모델로 표현할 수 있긴 하지만 그 확률 그래프 모델에서 추론을 진행하는 것 자체는 강화학습 문제를 푸는 것으로 연결되지 않는다. 보상의 개념이 외생변수로 취급되기 때문이다. 이 논문에서는 보상의 개념을 확률 그래프 모델에 포함하여 정책을 찾아내는 것을 추론 문제로 정의할 수 있게 하였다. 이러한 형태로 정의한다면 강화학습 문제를 일반화한 최대 엔트로피 강화학습 문제가 된다. 또한, 이 문제를 푸는 것은 결정적인 시스템에서는 exact 확률 추론과 동치이고 확률적인 시스템에서는 변분적 추론과 동치임을 보였다.
The Decision Making Problem and Terminology
먼저 강화학습에서 쓰이는 용어 정리이다. 상태를 \(\bold{s}\in\mathcal{S}\)로, 행동을 \(\bold{a}\in\mathcal{A}\)로 표현하고, 시스템의 역학 정보를 \(p(\bold{s}_{t+1}\mid\bold{s}_t,\bold{a}_t)\)로(상태 \(\bold{s}_t\)에서 행동 \(\bold{a}_t\)를 취했을 때 \(\bold{s}_{t+1}\)로 전이할 확률) 표현한다. 유한 시간 MDP를 고려하자. 보상함수는 \(r(\bold{s}_t,\bold{a}_t)\)라고 표기하고, 이 강화학습 문제를 푼다는 것은 기대 보상을 최대화하는 정책을 찾는 것, 또는 이 정책의 파라미터를 찾는 것으로 정의한다. 정책은 \(p(\bold{a}_{t}\mid\bold{s}_t,\theta)\)라고 표기한다. 상태 \(\bold{s}_t\)에서 \(\theta\)라는 파라미터로 정의된 함수가 알려주는 상태 \(\bold{a}_t\)를 취할 확률이다. 강화학습 문제를 푸는 것은 아래와 같이 표기할 수 있다.
\[\theta^\star=\arg\underset{\theta}{\max}\sum\limits^T_{t=1}\mathbb{E}_{(\bold{s}_t,\bold{a}_t)\sim p(\bold{s}_t,\bold{a}_t\mid\theta)}[r(\bold{s}_t,\bold{a}_t)]\]위 식에서 기댓값은 궤적의 확률분포 \(p(\tau)\) 에서 취해진다. 에피소드가 끝날때까지 방문했던 상태와 행동의 확률분포이다.
\[p(\tau)=p(\bold{s}_1,\bold{a}_1,\dots\bold{s}_T,\bold{a}_T\mid\theta)=p(\bold{s}_1)\prod\limits^T_{t=1}p(\bold{a}_t\mid\bold{s}_t,\theta)p(\bold{s}_{t+1}\mid\bold{s}_t,\bold{a}_t)\]정책 \(p(\bold{a}_t\mid\bold{s}_t,\theta)\)을 \(\pi_\theta(\bold{a}_t\mid\bold{s}_t)\)로 표기하기도 한다.
The Graphical Model
보상에 대한 정보를 가지고 있는 최적성 변수를 도입해서 RL 문제를 일반화하는 PGM을 만들자.
위에서 살펴본 제어 문제를 추론 문제로 정의하기 위해서는 최적 정책을 따랐을 때의 궤적이 가장 높은 확률로 발생하도록 확률 그래프 모형을 설계해야 한다. 즉, 사후 행동 조건부 확률분포 \(p(\bold{a}_t\mid\bold{s}_t,\theta)\)가 최적 정책을 가리키도록 해야 한다.
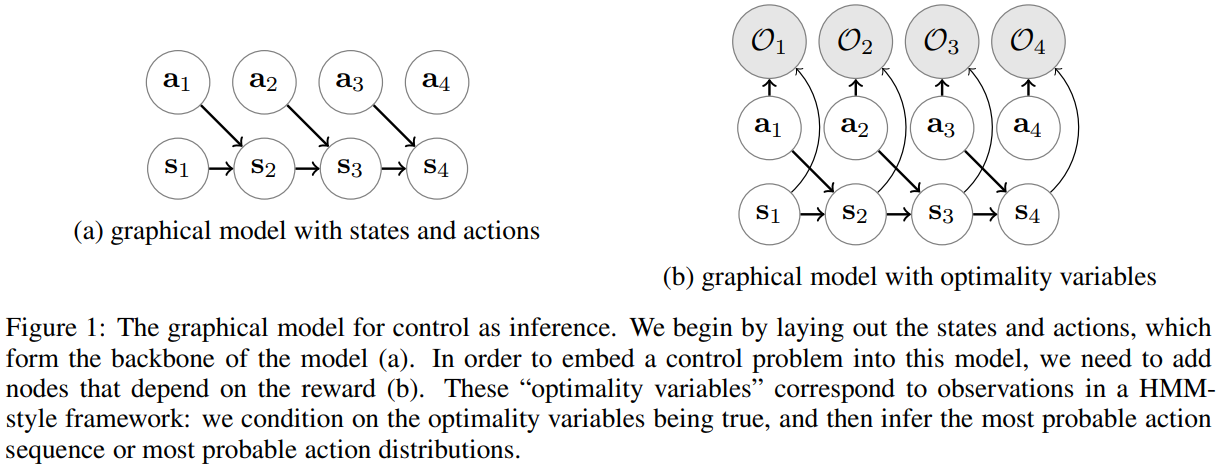
만약 강화학습 문제를 (a)와 같이 상태와 행동으로만 정의하면 보상에 대한 정보가 없기 때문에 제어 문제를 풀기에는 부족하다. 따라서 \(\mathcal{O}_t\)라는 이진 변수를 도입한다. \(\mathcal{O}_t\)는 최적성을 나타내며, \(\mathcal{O}_t=1\)일 경우 \(t\)시점에서 에이전트가 처한 상황(상태와 행동)이 최적임을 나타낸다고 정의한다. 이 논문에서는 \(\mathcal{O}_t\)의 분포를 아래와 같이 정의한다.
\[p(\mathcal{O}_t=1\mid\bold{s}_t,\bold{a}_t)=\text{exp}(r(\bold{s}_t,\bold{a}_t))\]임의적이라고 생각할 수도 있으나, 글을 따라가다보면 이 정의를 납득하게 될 것이다. 위의 정의에 따라 \(\mathcal{O}_{1:T}=1\)이 주어졌을 때 궤적의 사후분포를 생각해보자. (최적의 궤도가 샘플링될 확률이라고 이해하면 될 것 같다.)
\[p(\tau\mid\mathcal{O}_{1:T}=1)\propto p(\tau,\mathcal{O}_{1:T}=1)=p(\bold{s}_1)\prod\limits^T_{t=1}p(\mathcal{O}_{1:T}=1\mid\bold{s}_t,\bold{a}_t)p(\bold{s}_{t+1}\mid\bold{s}_t,\bold{a}_t)\\ =p(\bold{s}_1)\prod\limits^T_{t=1}\text{exp}(r(\bold{s}_t,\bold{a}_t))p(\bold{s}_{t+1}\mid\bold{s}_t,\bold{a}_t)\\ =\Bigg[p(\bold{s}_1)\prod\limits^T_{t=1}p(\bold{s}_{t+1}\mid\bold{s}_t,\bold{a}_t)\Bigg]\text{exp}\Bigg(\sum\limits^T_{t=1}r(\bold{s}_t,\bold{a}_t)\Bigg)\\ =p(\tau)\text{exp}\Bigg(\sum\limits^T_{t=1}r(\bold{s}_t,\bold{a}_t)\Bigg)\]간결한 표현을 위해서 \(\mathcal{O}_{t}=1\)을 \(\mathcal{O}_{t}\)로 나타낼 수 있다고 하자. 만약 시스템이 deterministic 하다면, \(p(\tau)\)는 0이나 1로 나타내어질 것이며, 가능한 궤적(\(p(\tau)=1\))에 한해서는 \(p(\tau\mid\mathcal{O}_{1:T})\)는 보상의 합과 지수적으로 비례하게 될 것이다. 즉, 보상을 많이 받을 수 있는 궤적의 확률이 높으며, 보상을 적게 받을수록 지수적으로 그 확률이 감소하게 된다. 최적성의 확률을 보상의 지수함수로 정의하게 됐을 때 얻는 이점이라고 할 수 있다.
Planning as Inference
위 확률 그래프 모형에서 3가지 추론을 진행할 수 있다.
-
Backward Messages \(\beta_t(\bold{s}_t,\bold{a}_t)=p(\mathcal{O}_{t:T}\mid\bold{s}_t,\bold{a}_t)\)
상태 \(\bold{s}_t\)에서 행동 \(\bold{a}_t\)를 택했을 때 이후 궤적이 최적일 확률
-
Policy \(p(\bold{a}_t\mid\bold{s}_t,\mathcal{O}_{1:T})\)
최적의 정책. 상태 \(\bold{s}_t\)에 있고 최적의 궤적을 따라갈 때 행동 \(\bold{a}_t\)를 택할 확률
-
Forward Messages \(\alpha_t(\bold{s}_t)=p(\bold{s}_t\mid\mathcal{O}_{1:t-1})\)
\(t-1\)까지 최적의 궤적을 따라서 \(\bold{s}_t\)를 방문하게 될 확률
Backward Message
먼저 backward message를 살펴보자.
\[\beta_t(\bold{s}_t,\bold{a}_t)=p(\mathcal{O}_{t:T}\mid\bold{s}_t,\bold{a}_t)\\ =\int p(\mathcal{O}_{t:T},\bold{s}_{t+1}\mid\bold{s}_t,\bold{a}_t)d\bold{s}_{t+1}\\ =\int p(\mathcal{O}_{t+1:T}\mid\bold{s}_{t+1})p(\bold{s}_{t+1}\mid\bold{s}_t,\bold{a}_t)p(\mathcal{O}_t\mid\bold{s}_t,\bold{a}_t)d\bold{s}_{t+1}\]Backward message를 미래 상태의 분포에 대해서 marginalize한 표현으로 쓰면 두번째 식이 나오고, \(\bold{s}_{t+1}\)에 대해서 조건을 주어서 \(\mathcal{O}_{t+1\dots T}\mid(\bold{s}_{t+1},\bold{s}_{t},\bold{a}_{t})=\mathcal{O}_{t+1\dots T}\mid\bold{s}_{t+1}\)인 점과 \(\mathcal{O}_t\)을 나머지 궤적으로부터 분리시키면 세번째 줄이 나온다.
근데 \(p(\mathcal{O}_t\mid\bold{s}_t,\bold{a}_t)\)는 \(\bold{s}_{t+1}\)에 의존하지 않기 때문에 밖으로 뺄 수 있고, \(p(\mathcal{O}_{t+1:T}\mid\bold{s}_{t+1})=\beta_{t+1}(\bold{s}_{t+1})\)이며, 적분 표현은 \(p(\bold{s}_{t+1}\mid\bold{s}_t,\bold{a}_t)\)의 분포를 따르는 \(\bold{s}_{t+1}\)에 대한 \(\beta_{t+1}(\bold{s}_{t+1})\)의 기댓값을 구하는 식이다. 즉,
\[\beta_t(\bold{s}_t,\bold{a}_t)=p(\mathcal{O}_t\mid\bold{s}_t,\bold{a}_t)\mathbb{E}_{\bold{s}_{t+1}\sim p(\bold{s}_{t+1}\mid\bold{s}_t,\bold{a}_t)}[\beta_{t+1}(\bold{s}_{t+1})]\]특히, 적분 안에 있는 첫번째 표현 \(p(\mathcal{O}_{t+1:T}\mid\bold{s}_{t+1})=\beta_{t+1}(\bold{s}_{t+1})\)을 다음 스텝에서 취하는 행동 \(\bold{a}_{t+1}\)에 대해서 marginalize하면,
\[p(\mathcal{O}_{t+1:T}\mid\bold{s}_{t+1})=\int p(\mathcal{O}_{t+1:T}\mid\bold{s}_{t+1},\bold{a}_{t+1})p(\bold{a}_{t+1}\mid\bold{s}_{t+1})d\bold{a}_{t+1}\]\(p(\mathcal{O}_{t+1:T}\mid\bold{s}_{t+1},\bold{a}_{t+1})=\beta_{t+1}(\bold{s}_{t+1},\bold{a}_{t+1})\)의 기댓값으로 표현할 수 있게 된다. \(t\)시점에서 보면
\[\beta_t(\bold{s}_t)=\mathbb{E}_{\bold{a}_t\sim p(\bold{a}_t\mid\bold{s}_t)}[\beta_t(\bold{s}_t,\bold{a}_t)]\]여기서 참고할 부분은 \(p(\bold{a}_t\mid\bold{s}_t)\)가 정책을 나타내는 것이 아니라는 것이다. 정책은 optimality index \(\mathcal{O}\)에 조건부인 \(p(\bold{a}_t\mid\bold{s}_t,\mathcal{O}_{1:T})\)로 나타내기로 한 것을 생각하자. \(p(\bold{a}_t\mid\bold{s}_t)\)는 이 분포를 따라 결정했을 때 따르는 궤적이 굳이 옵티멀일 필요가 없는, 어떻게 보면 행동의 사전분포인 것이다. 따라서 일단은 균등분포라고 가정한다.
이제 \(t=T-1\dots1\)일 때 \(\beta_t(\bold{s}_t)\)와 \(\beta_t(\bold{s}_t,\bold{a}_t)\) 사이의 관계를 나타내는 위 두 개의 식을 가지고 번갈아서 순차적으로 계산하면 \(\beta_t(\bold{s}_t)\)와 \(\beta(\bold{s}_t,\bold{a}_t)\)를 구할 수 있게 된다.
\[\text{For}\enspace t=T-1\enspace\text{to}\enspace1:\\ \quad\beta_t(\bold{s}_t,\bold{a}_t)=p(\mathcal{O}_t\mid\bold{s}_t,\bold{a}_t)\mathbb{E}_{\bold{s}_{t+1}\sim p(\bold{s}_{t+1}\mid\bold{s}_t,\bold{a}_t)}[\beta_{t+1}(\bold{s}_{t+1})]\\ \quad\beta_t(\bold{s}_t)=\mathbb{E}_{\bold{a}_t\sim p(\bold{a}_t\mid\bold{s}_t)}[\beta_t(\bold{s}_t,\bold{a}_t)]\]Policy
다음은 정책에 대한 추론이다. \(p(\bold{a}_t\mid\bold{s}_t,\mathcal{O}_{1:T})\)로 표현하는 정책은 궤적이 최적일 때, 상태 \(\bold{s}_t\)에서 행동 \(\bold{a}_t\)를 취할 확률로 나타낼 수 있다.
\[p(\bold{a}_t\mid\bold{s}_t,\mathcal{O}_{1:T})=\pi(\bold{a}_t\mid\bold{s}_t)\\ =p(\bold{a}_t\mid\bold{s}_t,\mathcal{O}_{t:T})\\ =\frac{p(\bold{a}_t,\bold{s}_t\mid\mathcal{O}_{t:T})}{p(\bold{s}_t\mid\mathcal{O}_{t:T})}\\ =\frac{p(\mathcal{O}_{t:T}\mid\bold{a}_t,\bold{s}_t)p(\bold{a}_t,\bold{s}_t)/p(\mathcal{O}_{t:T})}{p(\mathcal{O}_{t:T}\mid\bold{s}_t)p(\bold{s}_t)/p(\mathcal{O}_{t:T})}\\ =\frac{p(\mathcal{O}_{t:T}\mid\bold{a}_t,\bold{s}_t)}{p(\mathcal{O}_{t:T}\mid\bold{s}_t)}\frac{p(\bold{a}_t,\bold{s}_t)}{p(\bold{s}_t)}=\frac{\beta_t(\bold{s}_t,\bold{a}_t)}{\beta_t(\bold{s}_t)}p(\bold{a}_t\mid\bold{s}_t)\]상태 \(\bold{s}_t\)가 주어지면 \(t\)이전의 궤적에 대한 최적성은 상관 없다는 것과 간단한 베이즈 정리를 사용하면 위와 같이 나타낼 수 있다. 여기서 \(p(\bold{a}_t\mid\bold{s}_t)\)는 균등분포라고 가정하기로 했기 때문에 무시해도 괜찮다고 생각하면 (상수이다) 정책은 행동-상태 베타와 상태 베타의 비율로 이해할 수 있다.
\[\pi(\bold{a}_t\mid\bold{s}_t)=\frac{\beta(\bold{s}_t,\bold{a}_t)}{\beta(\bold{s}_t)}\]다시 한번 정리하면, 최적 궤적를 만들었던 정책은 평균적으로 상태 \(\bold{s}_t\)에서 시작해서 최적 궤적을 따르게 될 확률 대비 상태 \(\bold{s}_t\)에서 행동 \(\bold{a}_t\)를 취했을 때 최적 궤적을 따르게 될 확률을 따라서 행동을 취하는 것이다.
\(\beta\)를 사용하여 \(Q\)와 \(V\)를 정의한 것을 대입해보면,
\[\pi(\bold{a}_t\mid\bold{s}_t)=\text{exp}(Q_t(\bold{s}_t,\bold{a}_t)-V_t(\bold{s}_t))=\text{exp}(A_t(\bold{s}_t,\bold{a}_t))\]Advantage Function도 기존 강화학습에서 말하는 것과 똑같이 정의한다. 이제 정책은 위의 soft advantage가 변화함에 따라 지수적으로 바뀌는 확률에 따라 행동을 선택하게 된다. Advantage가 높은 행동을 지수적인 확률만큼 더 선택하게 되는 것이다. Make sense.
Forward Message
일단 \(\alpha_1(\bold{s}_1)=p(\bold{s}_1)\)이라고 정의하고 나머지는 위에서 정의한 바와 같이 \(\alpha_t=p(\bold{s}_t\mid\mathcal{O}_{1:t-1})\)라고 하자. 이제 backward message 추론과 같이 수식을 풀어보자. 이번에는 미래가 아닌 과거 상태와 행동에 대해 marginalization을 진행한다. \(t\)시점의 상태나 행동은 그 이전까지 궤적의 최적성과는 독립이라는 것을 기억하자.
\[\alpha_t(\bold{s}_t)=\int p(\bold{s}_t,\bold{s}_{t-1},\bold{a}_{t-1}\mid\mathcal{O}_{1:t-1})d\bold{s}_{t-1}d\bold{a}_{t-1}\\ =\int p(\bold{s}_t\mid\bold{s}_{t-1},\bold{a}_{t-1},\mathcal{O}_{1:t-1})p(\bold{a}_{t-1}\mid\bold{s}_{t-1},\mathcal{O}_{1:t-1})p(\bold{s}_{t-1}\mid\mathcal{O}_{1:t-1})d\bold{s}_{t-1}d\bold{a}_{t-1}\]시스템 역학 \(p(\bold{s}_t\mid\bold{s}_{t-1},\bold{a}_{t-1})=p(\bold{s}_t\mid\bold{s}_{t-1},\bold{a}_{t-1},\mathcal{O}_{1:t-1})\)이 알려져있다고 한다면 남은 것은 적분 안에 있는 두번째와 세번째 항이다.
\[p(\bold{a}_{t-1}\mid\bold{s}_{t-1},\mathcal{O}_{t-1})p(\bold{s}_{t-1}\mid\mathcal{O}_{1:t-1})=\\ \frac{p(\mathcal{O}_{t-1}\mid\bold{s}_{t-1},\bold{a}_{t-1})p(\bold{a}_{t-1}\mid\bold{s}_{t-1})}{p(\mathcal{O}_{t-1}\mid\bold{s}_{t-1})}\frac{p(\mathcal{O}_{t-1}\mid\bold{s}_{t-1})p(\bold{s}_{t-1}\mid\mathcal{O}_{1:t-2})}{p(\mathcal{O}_{t-1}\mid\mathcal{O}_{1:t-2})}\\ =\frac{p(\mathcal{O}_{t-1}\mid\bold{s}_{t-1},\bold{a}_{t-1})p(\bold{a}_{t-1}\mid\bold{s}_{t-1})p(\bold{s}_{t-1}\mid\mathcal{O}_{1:t-2})}{p(\mathcal{O}_{t-1}\mid\mathcal{O}_{1:t-2})}\]\(p(\bold{s}_{t-1}\mid\mathcal{O}_{1:t-2})=\alpha_{t-1}(\bold{s}_{t-1})\)임을 생각하면 이제 알고있는 정보로 \(\alpha_t(\bold{s}_t)\)를 계산할 수 있게 된다. 여기서 상태 주변분포 \(p(\bold{s}_t\mid\mathcal{O}_{1:T})\)는 어떻게 계산할까? 전체 궤적이 최적일 때 상태 \(\bold{s}_t\)에 방문할 확률이다. \(\mathcal{O}_{t:T}\mid\bold{s}_t\)는 \(\mathcal{O}_{1:t-1}\)에 독립이라는 것을 사용하면,
\[p(\bold{s}_t\mid\mathcal{O}_{1:T})=\frac{p(\bold{s}_t,\mathcal{O}_{1:T})}{p(\mathcal{O}_{1:T})}=\frac{p(\mathcal{O}_{t:T}\mid\bold{s}_t)p(\bold{s}_t,\mathcal{O}_{1:t-1})}{p(\mathcal{O}_{1:T})}\\ \propto p(\mathcal{O}_{t:T}\mid\bold{s}_t)p(\bold{s}_t\mid\mathcal{O}_{1:t-1})p(\mathcal{O}_{1:t-1})\propto\beta_t(\bold{s}_t)\alpha_t(\bold{s}_t)\]마지막에 \(p(\mathcal{O}_{1:t-1})\)은 상태 \(\bold{s}_t\)에 의존하지 않으므로 지금은 생각하지 않아도 된다. 즉, 상태 주변 분포는 forward message와 backward message의 곱으로 나타낼 수 있다.
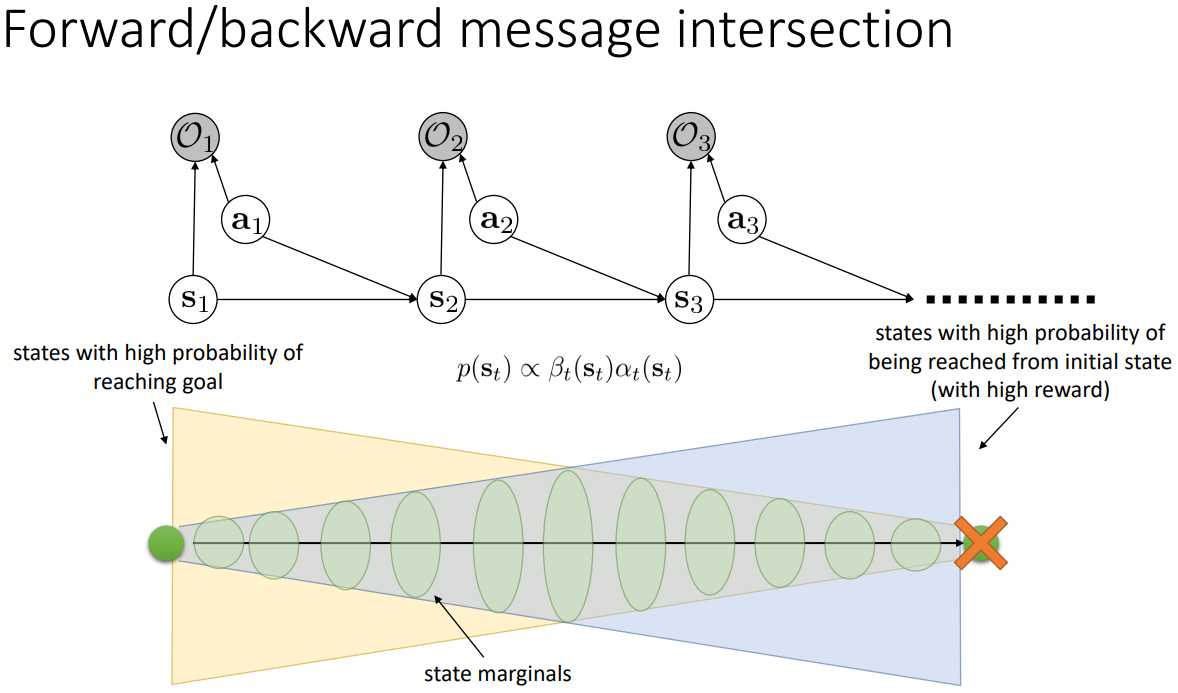
지금까지 살펴본 것을 정리하면 아래 사진과 같다. 시작점(\(\bold{s}_1\))과 목표점(\(\bold{s}_T\))이 있을 때 forward/backward message가 전달하고자 하는 바를 나타내주고 있다. 노란색 부분은 backward message의 의미를 표현한다. 목표점을 기준으로 생각해보자. 미래 궤도의 최적성이 높은 상태 \(\bold{s}_t\)의 개수는 \(T\)시점에 가까워질수록 줄어들게 되고 (목표까지 시간이 없다!), 시간을 거슬러 올라갈수록 \(T\)시점에 목표점에 도달할 수 있는 상태 \(\bold{s}_t\)의 수는 늘 것이다. 파란색 부분은 forward message의 의미를 표현한다. 지금까지 궤도가 최적일 때 방문할 수 있는 \(\bold{s}_t\)의 개수는 반대로 시작점에 가까울수록 적을 것이다. \(\bold{s}_1\)에서 시작해서 \(\bold{s}_T\)에 도착할 때까지 상태 \(\bold{s}_t\)에 방문할 확률은 고로 forward message와 backward message의 교집합으로 나타나고, 수식으로는 그 두 확률을 곱한 것이다.
Soft Values and Inference Procedure
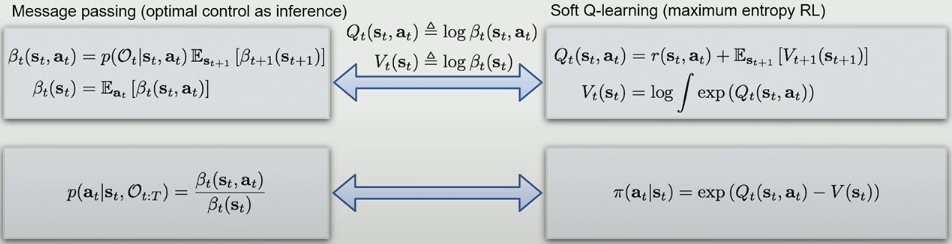
Backward Message Passing은 log space에서 Value Iteration의 soft 버전이다.
Backward Message를 구하는 방법과 Value Iteration을 같이 두고 비교해보자.
- Backward Message
- Value Iteration
비슷한 점을 찾을 수 있을까? 위 표현 그대로에서는 찾기 힘들 수도 있다. 하지만 약간 바꾸면 비슷한 점이 보일 것이다. 먼저 \(\beta\)의 정의를 잘 살펴보자. \(\beta_t(\bold{s}_t,\bold{a}_t)\)는 상태 \(\bold{s}_t\)에서 행동 \(\bold{a}_t\)를 취했을 때 따르게 되는 궤적이 최적일 확률이다. 이는 전통적인 강화학습에서 \(Q\)함수의 정의와 유사하다고 받아들일 수 있다. \(Q\)함수 \(Q(\bold{s}_t,\bold{a}_t)\)는 상태 \(\bold{s}_t\)에서 행동 \(\bold{a}_t\)를 취했을 때 얻는 할인된 보상 합의 기댓값이고, 보상을 많이 얻게 되면 최적일 확률이 높아지기 때문이다. 가치함수(\(V(\bold{s}_t)\)) 또한 비슷하게 생각할 수 있다. 따라서, soft Q-function, soft V-function을 정의해볼 수 있다. \(\beta\)를 정의한 확률이 보상의 exponential에 비례하기 때문에 \(\log\) 공간으로 보낸 것을 사용해서 정의해 보자.
\[V_t(\bold{s}_t)=\log\beta_t(\bold{s}_t)\\ Q_t(\bold{s}_t,\bold{a}_t)=\log\beta_t(\bold{s}_t,\bold{a}_t)\]이 표현을 위에서 살펴본 backward message를 구하는 방법에 대입하면 아래와 같은 식을 얻을 수 있다.
\[\text{For}\enspace t=T-1\enspace\text{to}\enspace1:\\ \quad Q_t(\bold{s}_t,\bold{a}_t)=r(\bold{s}_t,\bold{a}_t)+\log\mathbb{E}_{\bold{s}_{t+1}\sim p(\bold{s}_{t+1}\mid\bold{s}_t,\bold{a}_t)}[\exp(V_{t+1}(\bold{s}_{t+1}))]\\ \quad V_t(\bold{s}_t)=\mathbb{E}_{\bold{a}_t\sim p(\bold{a}_t\mid\bold{s}_t)}[\exp(Q_t(\bold{s}_t,\bold{a}_t))]=\log\int\exp(Q_t(\bold{s}_t,\bold{a}_t))d\bold{a}_t\]첫번째 표현은 정의를 그대로 대입하고 \(p(\mathcal{O}_t\mid\bold{s}_t,\bold{a}_t)=\text{exp}(r(\bold{s}_t,\bold{a}_t))\)임을 사용하면 바로 얻을 수 있는데, 시스템이 결정적이라고 가정한다면 \(\log\)와 \(\exp\)가 서로 상쇄되면서 \(Q_t(\bold{s}_t,\bold{a}_t)=r(\bold{s}_t,\bold{a}_t)+V_{t+1}(\bold{s}_{t+1})\)이 된다. 정확히 Bellman backup 표현을 얻는 것이다.
이제 두번째 줄을 보자. 행동의 사전분포 \(p(\bold{a}_t\mid\bold{s}_t)\)가 균등분포라는 가정을 사용하여 얻을 수 있다. \(Q\)값이 크면 지수함수가 취해졌기 때문에 \(Q\)값 사이의 차이도 커질 것이고, 제일 큰 \(Q\)값이 \(\log\int\exp(Q_t(\bold{s}_t,\bold{a}_t))d\bold{a}_t\)을 dominate할 것이다. 즉, \(V_t(\bold{s}_t)\rightarrow\underset{\bold{a}_t}{\text{max}}\,Q_t(\bold{s}_t,\bold{a}_t)\)가 되는 것을 볼 수 있다. 어떠한 의미에서 ‘soft’max라고 할 수 있는 것이다. 뉴럴넷 모델링에서 자주 나오는 활성화함수 소프트맥스와는 용어는 같지만 다르다. 주의할 것. \(\text{max}\)오퍼레이터의 ‘soft’버전이라서 softmax라고 부르는 것이다. 이제 backward message와 value iteration을 다시 적어보자.
- Backward Message
- Value Iteration
둘 사이 유사성이 보일 것이다. Soft Q와 soft V 함수를 사용한다면 시스템 역학이 결정적이라는 가정 하에 backward message를 구하는 방법이 value iteration과 거의 동일해진다. \(Q\)와 \(V\)의 soft버전을 사용한다는 것과 Softmax를 쓰는 것이 차이점이다. 원래 강화학습 문제 정의에서 선형으로 정의되던 관계를 \(\exp\)공간으로 보내 곱하기 연산으로 잘 옮겨지게 PGM을 정의한 것이라고 볼 수 있을 것 같다. 2018년 NIPS Infer2Control에서 Levine의 발표자료를 참고하자.
Optimization Problem
정책 찾기 문제는 \(D_{\text{KL}}(\hat{p}(\tau)\lVert p(\tau))\)를 최소화하는 문제이며, MaxEntRL을 푸는 문제와 동일하다.
위에서 살펴본 정책을 얻는 추론 문제를 최적화 문제로 생각해보자. \(p(\bold{a}_t\mid\bold{s}_t,\mathcal{O}_{1:T})\)는 전체 궤적 \(p(\tau\mid\mathcal{O}_{1:T})\)를 각 \(s_t\)에 조건부 확률을 취하면 얻을 수 있다. 시스템이 결정적이면 궤도의 확률분포는 아래와 같이 나타낼 수 있음을 보았다.
\[p(\tau\mid\mathcal{O}_{1:T}=1)\propto \mathbb{I}[p(\tau\neq0)]\text{exp}\Bigg(\sum\limits^T_{t=1}r(\bold{s}_t,\bold{a}_t)\Bigg)\]또한, 우리가 찾고자 하는 정책 함수가 \(\pi(\bold{a}_t\mid\bold{s}_t)\)라고 하면 이를 사용한 궤도는 아래와 같다.
\[\hat{p}(\tau)\propto\mathbb{I}[p(\tau)\neq0]\prod\limits^T_{t=1}\pi(\bold{a}_t\mid\bold{s}_t)\]결국 위 두 개의 궤적 확률분포가 서로 최대한 가까워지게 하는 정책 함수를 찾는 문제이다. 시스템이 결정적이고 행동의 사전분포가 균등분포인 경우에는 추론을 마쳤을 때 위 두 표현이 완전히 같게 되기 때문이다. 정책의 곱으로 나타나있는 표현 \(\hat{p}(\tau)\)에 \(\pi\) 대신 \(\beta\)함수의 비율을 대입하고 backward message 식 두개를 사용해 구한 \(\beta\)함수 표현을 사용하면, 분모와 분자에 있는 \(\beta\)표현이 약분되어 없어지고 남는 것은 \(p(\mathcal{O}_t\mid\bold{s}_t,\bold{a}_t)\)들의 곱이다. 즉, \(D_{\text{KL}}(\hat{p}(\tau)\lVert p(\tau))=0\)이다. 그렇다면 정책을 구하는 추론 문제를 \(D_{\text{KL}}(\hat{p}(\tau)\lVert p(\tau))\)를 최소화하는 문제라고 받아들일 수 있다. 이제 목적함수 \(D_{\text{KL}}(\hat{p}(\tau)\lVert p(\tau))\) 의 정의를 쓰는 것으로 시작하여 수식을 정리해보자.
\[D_{\text{KL}}(\hat{p}(\tau)\lVert p(\tau))=-\mathbb{E}_{\tau\sim\hat{p}(\tau)}[\log p(\tau)-\log\hat{p}(\tau)]\]양변에 음수를 곱하고 \(p(\tau)\)와 \(\hat{p}(\tau)\) 를 나타내는 식을 대입해보자.
\[-D_{\text{KL}}(\hat{p}(\tau)\lVert p(\tau))\\ =\mathbb{E}_{\tau\sim\hat{p}(\tau)}\bigg[\log p(\bold{s}_1)+\sum\limits^T_{t=1}(\log p(\bold{s}_{t+1}\mid\bold{s}_t,\bold{a}_t)+r(\bold{s}_t,\bold{a}_t))\\ \qquad\qquad-\log p(\bold{s}_1)-\sum\limits^T_{t=1}(\log p(\bold{s}_{t+1}\mid\bold{s}_t,\bold{a}_t)+\log\pi(\bold{a}_t\mid\bold{s}_t))\bigg]\\ =\mathbb{E}_{\tau\sim\hat{p}(\tau)}\bigg[\sum\limits^T_{t=1}r(\bold{s}_t,\bold{a}_t)-\log\pi(\bold{a}_t,\bold{s}_t)\bigg]\\ =\sum\limits^T_{t=1}\mathbb{E}_{(\bold{s}_t,\bold{a}_t)\sim\hat{p}(\bold{s}_t,\bold{a}_t)}[r(\bold{s}_t,\bold{a}_t)-\log\pi(\bold{a}_t\mid\bold{s}_t)]\\ =\sum\limits^T_{t=1}\mathbb{E}_{(\bold{s}_t,\bold{a}_t)\sim\hat{p}(\bold{s}_t,\bold{a}_t)}[r(\bold{s}_t,\bold{a}_t)]+\mathbb{E}_{(\bold{s}_t)\sim\hat{p}(\bold{s}_t)}[\mathcal{H}(\pi(\bold{a}_t\mid\bold{s}_t))]\]마지막 줄은 엔트로피의 정의에 따라서 도출된다. 결과를 정리하면, 시스템이 결정적이고 행동 사전분포가 균등분포인 경우에 PGM을 정의하여 정책에 대한 추론을 진행하는 것은 강화학습에서 다루는 보상과 정책의 엔트로피를 최대화하는 것과 같다. 이런 식의 문제를 최대 엔트로피 강화학습 문제라고 한다.
Relaxation of Assumptions
지금까지 가정한 두 가지, 시스템이 결정적이라는 것과 행동의 사전분포가 균등분포라는 점을 완화해보자. 먼저 행동의 사전분포가 균등이 아닐 경우를 살펴본다. 더 이상 \(p(\bold{a}_t\mid\bold{s}_t)\)를 생략할 수 없다면 soft \(V\) function은 아래와 같이 될 것이다.
\[V(\bold{s}_t)=\log\int\exp(Q_t(\bold{s}_t,\bold{a}_t)+\log p(\bold{a}_t\mid\bold{s}_t))d\bold{a}_t\]그럼 soft \(Q\) function을 아래와 같이 다르게 정의해보자.
\[\tilde{Q}(\bold{s}_t,\bold{a}_t)=r(\bold{s}_t,\bold{a}_t)+\log p(\bold{a}_t\mid\bold{s}_t)+\log\mathbb{E}[\exp(V(\bold{s}_{t+1}))]\]이제 \(\tilde{Q}\)를 사용하여 \(V\)를 표현할 수 있다.
\[V(\bold{s}_t)=\log\int\exp(\tilde{Q}_t(\bold{s}_t,\bold{a}_t))d\bold{a}_t=\log\int\exp(Q_t(\bold{s}_t,\bold{a}_t)+\log p(\bold{a}_t\mid\bold{s}_t))d\bold{a}_t\]\(V\)와 \(\tilde{Q}\)를 가지고 위의 backward message구하는 반복문을 reproduce할 수 있게 된다. \(\tilde{Q}\)의 정의에서 \(\log p(\mathcal{O}_t\mid\bold{s}_t,\bold{a}_t)=r(\bold{s}_t,\bold{a}_t)+\log p(\bold{a}_t\mid\bold{s}_t)\)으로 두었기 때문이라고 이해할 수 있다. 행동의 사전분포는 보상함수를 통해 최적성에 녹아들게 된다. 따라서 행동의 사전분포가 균등분포라는 가정을 일반성을 잃지 않고 사용할 수 있는 것이다.
다음 부분에서는 시스템이 결정적이지 않고 확률적일 때 어떠한 접근법을 취해야 하는지 살펴본다.
Variational Inference and Stochastic Dynamics
확률적 시스템에서는 위의 방법을 그대로 쓸 수 없다.
만약 시스템 역학이 확률적이거나, 시스템 역학에 대한 정보가 없어서 확률적으로 추정을 해야하는 경우에는 위의 방식을 그대로 적용하기 힘들다. Backward message를 구하는 방법에서 첫 줄을 보자.
\[Q_t(\bold{s}_t,\bold{a}_t)=r(\bold{s}_t,\bold{a}_t)+\log\mathbb{E}_{\bold{s}_{t+1}\sim p(\bold{s}_{t+1}\mid\bold{s}_t,\bold{a}_t)}[\exp(V_{t+1}(\bold{s}_{t+1}))]\]이 표현은 시스템이 결정적일 때는 일반 Bellman backup과 똑같았다. 하지만 시스템이 확률적일 때는 어떠한 일이 일어나는지 생각해보자. 쉬운 설명을 위해서 상태가 이산적이라고 가정한다. 10000개라고 하자. 만약 1개의 상태의 \(V\)값이 굉장히 크고 나머지 9999개 상태의 \(V\)값이 굉장히 작다면 \(\log\mathbb{E}_{\bold{s}_{t+1}\sim p(\bold{s}_{t+1}\mid\bold{s}_t,\bold{a}_t)}[\exp(V_{t+1}(\bold{s}_{t+1}))]\)는 어떻게 될까? 만약 \(\log\)와 \(\exp\)이 없는 일반적인 강화학습 Bellman backup 표현일 때는 일반적으로 이 값이 작을 것이다. 9999개 상태의 작은 \(V\)값을 상쇄하고도 남을 만큼 1개 상태로 전이할 확률이 어마어마하게 크지 않은 이상 말이다. 물론 그 1개의 상태로 거의 확실히 전이한다면 \(V\)는 큰 값을 가지는 것이 마땅하다. 하지만 그렇지 않은 경우를 생각해보자. 만약 \(V\)값이 굉장히 큰 1개의 상태에 전이할 확률이 크지 않다면? \(\log\mathbb{E}_{\bold{s}_{t+1}\sim p(\bold{s}_{t+1}\mid\bold{s}_t,\bold{a}_t)}[\exp(V_{t+1}(\bold{s}_{t+1}))]\)는 이러한 상황에서도 큰 값을 가지게 된다. \(\exp\)가 안에 들어있기 때문에 저 표현 자체를 dominate하는 것이다. 큰 문제이다. \(Q\)값이 optimistic하다고 표현한다. 왜 이런 일이 발생하는 것일까?
이유는 이 문제에 접근하는 가정과 과정이 확률적인 시스템에 부합하지 않기 때문이다. 시스템 역학이 확률적일 때 궤적의 확률분포를 써보자.
\[p(\hat\tau)=p(\bold{s}_1\mid\mathcal{O}_{1:T})\prod\limits^T_{t=1}p(\bold{s}_{t+1}\mid\bold{s}_t,\bold{a}_t,\mathcal{O}_{1:T})p(\bold{a}_t\mid\bold{s}_t,\mathcal{O}_{1:T})\]시스템 역학이 결정적일 때에는 역학 전이 분포 \(p(\bold{s}_{t+1}\mid\bold{s}_t,\bold{a}_t)=p(\bold{s}_{t+1}\mid\bold{s}_t,\bold{a}_t,\mathcal{O}_{1:T})\)이어야만 했다. 전이 방법이 한 가지밖에 존재하지 않기 때문이다. 하지만, 확률적 시스템에서는 그렇지 않기 때문에 초기 상태 분포와 시스템 전이 분포에 모두 \(\mathcal{O}\)가 조건부로 들어가 있는 것을 볼 수 있다. (\(p(\bold{s}_{t+1}\mid\bold{s}_t,\bold{a}_t,\mathcal{O}_{1:T})\neq p(\bold{s}_{t+1}\mid\bold{s}_t,\bold{a}_t)\)) 하지만 \(p(\bold{s}_{t+1}\mid\bold{s}_t,\bold{a}_t,\mathcal{O}_{1:T})\)은 우리가 원하는 것이 아니다. 전이 분포는 궤적의 최적성과는 관계가 없어야 하는데, 최적을 가정하고 얻는 전이 분포의 식이 들어가 있다. 이대로 추론을 진행하면 오히려 전이 분포를 조작하는 효과가 있는 것이다.
Optimization Problem
확률적 시스템에서도 Backward Message Passing과 DP로 정책 찾기가 가능하다.
간단하게 이 문제를 회피하기 위해서 \(p(\bold{s}_{t+1}\mid\bold{s}_t,\bold{a}_t,\mathcal{O}_{1:T})\)대신 \(p(\bold{s}_{t+1}\mid\bold{s}_t,\bold{a}_t)\)를 사용해서 궤적의 확률분포를 나타냈을 때 최적화 문제가 어떻게 바뀌는지 보자.
\[p(\hat\tau)=p(\bold{s}_1\mid\mathcal{O}_{1:T})\prod\limits^T_{t=1}p(\bold{s}_{t+1}\mid\bold{s}_t,\bold{a}_t)\pi(\bold{a}_t\mid\bold{s}_t)\]결정적 시스템일 때 방법을 그대로 적용하면 목적함수인 궤적간의 KL발산은 아래와 같은 꼴을 가지게 된다.
\[-D_{\text{KL}}(\hat{p}(\tau)\lVert p(\tau))=\sum\limits^T_{t=1}\mathbb{E}_{(\bold{s}_t,\bold{a}_t)\sim\hat{p}(\bold{s}_t,\bold{a}_t)}[r(\bold{s}_t,\bold{a}_t)+\mathcal{H}(\pi(\bold{a}_t\mid\bold{s}_t))]\]결정적 시스템일 때와 표현이 똑같지만, 이제는 시스템의 전이확률에 대해서 기댓값을 구해야 한다는 점이 추가되었다. 이 표현에서 동적계획법을 통해 확률적 시스템의 backward message를 도출해보자. 결정적인 시스템에서 backward message를 도출했을 때와 마찬가지로 \(T\)시점에서 뒤로 돌아갈것이다. \(\pi(\bold{a}_T\mid\bold{s}_T)\) 에 대해서 최적화해보자. 아래의 식을 최대화하는 것이다.
\[\mathbb{E}_{(\bold{s}_T,\bold{a}_T)\sim\hat{p}(\bold{s}_T,\bold{a}_T)}[r(\bold{s}_T,\bold{a}_T)-\log\pi(\bold{a}_T\mid\bold{s}_T)]=\\ \mathbb{E}_{\bold{s}_T\sim\hat{p}(\bold{s}_T)}\bigg[-D_{\text{KL}}\bigg(\pi(\bold{a}_T\mid\bold{s}_T)\lVert\frac{1}{\exp(V(\bold{s}_T))}\exp(r(\bold{s}_T,\bold{a}_T))\bigg)+V(\bold{s}_T)\bigg]\]\(V(\bold{s}_T)=\log\int_{\mathcal{A}}\exp(r(\bold{s}_T,\bold{a}_T))d\bold{a}_T\)으로 정의하면 \(\exp(V(\bold{s}_T))\)는 \(\exp(r(\bold{s}_T,\bold{a}_T))\)의 정규화항이 된다. \(T\)시점의 행동에 대해서 정규화를 해주는 것이다. KL발산은 두 분포가 동일할 때 최소값을 가지므로 KL발산 안에 있는 두 항이 같다고 두면 아래와 같이 \(\pi(\bold{a}_T\mid\bold{s}_T)\)를 구할 수 있게 된다.
\[\pi(\bold{a}_T\mid\bold{s}_T)=\exp(r(\bold{s}_T,\bold{a}_T)-V(\bold{s}_T))\]비슷하게, 각 \(t\)시점에 대해서 아래의 항을 최대화하는 정책 \(\pi(\bold{a}_t\mid\bold{s}_t)\)를 구하면 각 시점에서 정책을 구할 수 있게 된다.
\[\mathbb{E}_{(\bold{s}_t,\bold{a}_t)\sim\hat{p}(\bold{s}_t,\bold{a}_t)}[r(\bold{s}_t,\bold{a}_t)-\log\pi(\bold{a}_t\mid\bold{s}_t)]+\mathbb{E}_{(\bold{s}_t,\bold{a}_t)\sim\hat{p}(\bold{s}_t,\bold{a}_t)}[\mathbb{E}_{\bold{s}_{t+1}\sim\hat{p}(\bold{s}_{t+1}\mid\bold{s}_t,\bold{a}_t)}[V(\bold{s}_{t+1})]]\]첫번째 항은 \(T\)시점에서 본 목적함수와 같은 것이고, 두번째 항은 \(\pi(\bold{a}_t\mid\bold{s}_t)\)가 미래 궤적에 미치는 기여도를 나타내는 항이다. \(T\)시점에서 KL발산 항을 최소로(0으로) 만들면 \(V(\bold{s}_T)\)가 남는 것을 볼 수 있는데, 각 시점에서 이 \(V\)항이 쌓이기 때문에 이 두번째 항이 필요한 것이다. 목적함수가 조금 바뀌었으니 여기서 결정적 시스템에서와 마찬가지로 \(Q\)와 \(V\)함수를 정의하자. 뒤에 남는 \(V\)항까지 포함할 수 있는 정의이다.
\[Q(\bold{s}_t,\bold{a}_t)=r(\bold{s}_t,\bold{a}_t)+\mathbb{E}_{\bold{s}_{t+1}\sim p(\bold{s}_{t+1}\mid\bold{s}_t,\bold{a}_t)}[V(\bold{s}_{t+1})]\\ V(\bold{s}_t)=\log\int_{\mathcal{A}}\exp(Q(\bold{s}_t,\bold{a}_t))d\bold{a}_t\]Bellman backup과 동일한 표현을 또 얻었다. 이렇게 정의하면 새 목적함수는 아래와 같은 형태를 가지게 된다. (네 간단한 연산입니다.)
\[\mathbb{E}_{\bold{s}_t\sim\hat{p}(\bold{s}_t)}\bigg[-D_{\text{KL}}\bigg(\pi(\bold{a}_t\mid\bold{s}_t)\lVert\frac{1}{\exp(V(\bold{s}_t))}\exp(Q(\bold{s}_t,\bold{a}_t))\bigg)+V(\bold{s}_t)\bigg]\]이제 KL항을 최소로 만들 수 있게 \(\pi(\bold{a}_t\mid\bold{s}_t)=\exp(Q(\bold{s}_t,\bold{a}_t)-V(\bold{s}_t))\)라고 두면 \(\mathbb{E}_{\bold{s}_t\sim\hat{p}(\bold{s}_t)}[V(\bold{s}_t)]\)항이 남게 된다. 동적계획법으로 \(T\)시점부터 대입하여 답을 구할 수 있게 되었다.
중요한 것은 이 풀이방법을 얻기 위해 정의한 \(Q\)와 \(V\)함수다. 확률적 시스템에서 문제가 되었던 백업 방법은 아래와 같았다.
\[Q_t(\bold{s}_t,\bold{a}_t)=r(\bold{s}_t,\bold{a}_t)+\log\mathbb{E}_{\bold{s}_{t+1}\sim p(\bold{s}_{t+1}\mid\bold{s}_t,\bold{a}_t)}[\exp(V_{t+1}(\bold{s}_{t+1}))]\]전이확률 조작의 결과로 optimistic한 \(Q\)값이 계산된다는 점이었다. 반면 초기 상태 확률과 전이확률을 고정시킨 상태에서 얻은 백업 방법은 아래와 같다.
\[Q(\bold{s}_t,\bold{a}_t)=r(\bold{s}_t,\bold{a}_t)+\mathbb{E}_{\bold{s}_{t+1}\sim p(\bold{s}_{t+1}\mid\bold{s}_t,\bold{a}_t)}[V(\bold{s}_{t+1})]\]로그와 지수함수가 없어진 것을 볼 수 있다. 더이상 \(Q\)함수가 optimistic이 아니게 되어 문제가 사라졌다. 이번 부분에서는 최적화문제를 잘 정의하여 확률적 시스템의 문제를 해결하는 방법을 알아봤다면, 다음 부분에서는 확률적 시스템의 문제를 확률적 추론으로 해결하는 방법을 알아볼 것이다.
Control as Variational Inference
확률적 시스템에서 정책을 찾는 문제는 변분적 추론으로 정의가 가능하며, 이 또한 \(D_{\text{KL}}(q(\tau)\lVert p(\mathcal{O}_{1:T},\tau))\)를 최소화하는 문제이고, 역시 MaxEntRL 문제를 푸는 것과 같다.
확률적 시스템에서 마주하는 문제를 정리하면 아래와 같다.
- 우리가 원하는 것: \(p(\bold{a}_t\mid\bold{s}_t,\mathcal{O}_{1:T})\)
- 우리가 원치 않는것: \(p(\bold{s}_{t+1}\mid\bold{s}_t,\bold{a}_t,\mathcal{O}_{1:T})\neq p(\bold{s}_{t+1}\mid\bold{s}_t,\bold{a}_t)\)
확률적 추론 프레임워크에서는 이 문제를 해결하기 위해 궤적의 확률분포를 근사하는 다른 함수를 찾을 것이다. 특히, 우리가 풀고자 하는 문제에 맞게 \(p(\bold{s}_{1:T},\bold{a}_{1:T}\mid\mathcal{O}_{1:T})\)와 비슷하지만 \(p(\bold{s}_{t+1}\mid\bold{s}_t,\bold{a}_t)\)와 같은 전이함수를 가지는 함수 \(q(\bold{s}_{1:T},\bold{a}_{1:T})\)를 만들 것이다. 궤적의 확률분포를 나타내는 \(q(\bold{s}_{1:T},\bold{a}_{1:T})\)를 초기정책 확률분포, 전이 확률분포, 정책으로 분해할 것인데, 초기 상태 확률분포와 전이 확률분포는 시스템의 정보를 그대로 가져와서 고정할 것이다. 그리고 정책에 해당하는 확률분포로는 새로운 함수를 도입하면 전이 확률분포와 초기 상태 확률분포가 고정되어있어야 한다는 조건을 만족하게 된다.
\[q(\bold{s}_{1:T},\bold{a}_{1:T})=q(\bold{s}_1)\prod_tq(\bold{s}_{t+1}\mid\bold{s}_t,\bold{a}_t)q(\bold{a}_t\mid\bold{s}_t)\\ =p(\bold{s}_1)\prod_tp(\bold{s}_{t+1}\mid\bold{s}_t,\bold{a}_t)q(\bold{a}_t\mid\bold{s}_t)\]이제 변분적 추론이 등장한다. 변분적 추론은 \(p(z\mid x)\)를 근사하는 \(q(z)\)를 찾을 때 주로 쓰였는데, 이 맥락에서는 \(x=\mathcal{O}_{1:T},z=(\bold{s}_{1:T},\bold{a}_{1:T})\)라고 하면 정확히 우리가 원하는 것을 이룰 수 있다는 걸 알 수 있다. 근사하고자 하는 궤적의 확률은 \(p(\bold{s}_{1:T},\bold{a}_{1:T}\mid\mathcal{O}_{1:T})\)이고 우리가 가지고 있는 것은 \(q(\bold{s}_{1:T},\bold{a}_{1:T})\)이기 때문이다. Variational lower bound를 구해보자.
\[\log p(\mathcal{O}_{1:T})=\log\int\int p(\mathcal{O}_{1:T},\bold{s}_{1:T},\bold{a}_{1:T})d\bold{s}_{1:T}d\bold{a}_{1:T}\\ =\log\int\int p(\mathcal{O}_{1:T},\bold{s}_{1:T},\bold{a}_{1:T})\frac{q(\bold{s}_{1:T},\bold{a}_{1:T})}{q(\bold{s}_{1:T},\bold{a}_{1:T})}d\bold{s}_{1:T}d\bold{a}_{1:T}\\ =\log\mathbb{E}_{(\bold{s}_{1:T},\bold{a}_{1:T})\sim(q(\bold{s}_{1:T},\bold{a}_{1:T}))}[\frac{p(\mathcal{O}_{1:T},\bold{s}_{1:T},\bold{a}_{1:T})}{q(\bold{s}_{1:T},\bold{a}_{1:T})}]\\ \ge\mathbb{E}_{(\bold{s}_{1:T},\bold{a}_{1:T})\sim q(\bold{s}_{1:T},\bold{a}_{1:T})}[\log p(\mathcal{O}_{1:T},\bold{s}_{1:T},\bold{a}_{1:T})-\log q(\bold{s}_{1:T},\bold{a}_{1:T})]\\ =-D_{\text{KL}}(q(\tau)\lVert p(\mathcal{O}_{1:T},\tau))\]\(q(\bold{s}_{t+1}\mid\bold{s}_t,\bold{a}_t)=p(\bold{s}_{t+1}\mid\bold{s}_t,\bold{a}_t)\)임을 사용하면,
\[\log p(\mathcal{O}_{1:T})\ge\\ \mathbb{E}_{(\bold{s}_{1:T},\bold{a}_{1:T})\sim q(\bold{s}_{1:T},\bold{a}_{1:T})}[\log p(\bold{s}_1)+\sum\limits^T_{t=1}\log p(\bold{s}_{t+1}\mid\bold{s}_t,\bold{a}_t)+\sum\limits^T_{t=1}\log p(\mathcal{O}_t\mid\bold{s}_t,\bold{a}_t)\\ \qquad\qquad\qquad-\log p(\bold{s}_1)-\sum\limits^T_{t=1}\log p(\bold{s}_{t+1}\mid\bold{s}_t,\bold{a}_t)-\sum\limits^T_{t=1}\log q(\bold{a}_t\mid\bold{s}_t)]\\ =\mathbb{E}_{(\bold{s}_{1:T},\bold{a}_{1:T})\sim q(\bold{s}_{1:T},\bold{a}_{1:T})}\bigg[\sum\limits_tr(\bold{s}_t,\bold{a}_t)-\log q(\bold{a}_t\mid\bold{s}_t)\bigg]\\ =\sum\limits_t\mathbb{E}_{(\bold{s}_t,\bold{a}_t)\sim q(\bold{s}_t,\bold{a}_t)}[r(\bold{s}_t,\bold{a}_t)+\mathcal{H}(q(\bold{a}_t\mid\bold{s}_t))]\]익숙한 표현이 나왔다. 보상 뿐 아니라 정책의 엔트로피도 최대화하는 문제가 된 것이다. 결정적인 시스템뿐 아니라 확률적인 시스템에서도 같은 목적함수를 최대화하는 것이 확률적 추론을 통해 정책을 찾는 문제를 푸는 것이다. 그럼 이 문제를 어떻게 풀 수 있을까? 바로 위에서 살펴본 동적계획법 풀이에서 \(\pi\)자리에 \(q(\bold{a}_t\mid\bold{s}_t)\)를 넣으면 똑같은 방법으로 풀 수 있다. 정리하자면, 아래와 같은 ‘soft’ Value Iteration방법을 적용해서 \(Q\)와 \(V\)를 찾고, 동적계획법을 통해서 정책을 찾을 수 있다.
\[\text{For}\enspace t=T-1\enspace\text{to}\enspace1:\\ \quad Q_t(\bold{s}_t,\bold{a}_t)\leftarrow r(\bold{s}_t,\bold{a}_t)+\mathbb{E}[V_{t+1}(\bold{s}_{t+1})]\\ \quad V_t(\bold{s}_t)\leftarrow\text{softmax}_\bold{a_t}Q_t(\bold{s}_t,\bold{a}_t)\]이 방법을 두 가지로 확장할 수 있다. 첫번째 줄을 \(Q_t(\bold{s}_t,\bold{a}_t)\leftarrow r(\bold{s}_t,\bold{a}_t)+\gamma\mathbb{E}[V_{t+1}(\bold{s}_{t+1})]\)로 써서 할인율을 감안하는 모델을 만들 수도 있고, 두 번째 줄에서 softmax의 정도를 나타내는 temperature parameter \(\alpha\)를 도입하여 \(\alpha\log\int\exp(\frac{1}{\alpha}Q_t(\bold{s}_t,\bold{a}_t))d\bold{a}_t\)로 바꾸면 얼마나 soft한 max를 취할 건지를 조정할 수도 있다. \(\alpha\)가 0에 가까워질수록 결정적인, \(\max\)오퍼레이터와 비슷하게 되고, \(\alpha\)가 1에 가까워질수록 soft해진다.
정리하면, \(q(\tau)\)와 \(p(\mathcal{O}_{1:T},\tau)\)의 거리를 좁히는 것은 ELBO를 최적화하는 것과 같으며, 이는 최대 엔트로피 강화학습 문제를 푸는것과 같다.
Approximate Inference with Function Approximation
Soft Q-Learning, Soft PG, Soft Actor-Critic 모두 이 철학을 가지고 있었다!
앞서 동적계획법을 사용해 Soft \(Q\)와 soft \(V\)함수를 구하는 법을 알아보았다. 이번에는 함수 근사 방법을 활용하여 고차원이나 연속적인 도메인, 혹은 시스템 역학이 알려지지 않은 상황에서도 사용할 수 있는 실용적인 알고리즘을 살펴볼 것이다. 일반 강화학습 문제에서 제시되었던 Q-Learning, Policy Gradients, Actor-Critic방법의 soft한 버전이라고 생각하면 될 것이다.
Soft Q-Learning
가장 직관적으로 생각할 수 있는 적용방안은 일반 강화학습 문제에서 정의하는 Q-Learning에 softmax를 적용하는 방법일 것이다. 함수근사를 사용한 일반 Q-Learning알고리즘은 아래와 같다.
\[\phi\leftarrow\phi+\alpha\nabla_\phi Q_\phi(\bold{s},\bold{a})(r(\bold{s},\bold{a})+\gamma V(\bold{s}')-Q_\phi(\bold{s},\bold{a}))\\ V(\bold{s}')=\underset{\bold{a}'}{\max}Q_\phi(\bold{s}',\bold{a}')\]당연히 최적 정책은 각 상태에서 제일 높은 \(Q\)값을 가지는 행동을 택하는 것이 된다. 여기서 자연스럽게 \(\max\)를 \(\text{soft}\max\)로 바꾸어서 생각하자.
\[\phi\leftarrow\phi+\alpha\nabla_\phi Q_\phi(\bold{s},\bold{a})(r(\bold{s},\bold{a})+\gamma V(\bold{s}')-Q_\phi(\bold{s},\bold{a}))\\ V(\bold{s}')=\text{soft}\underset{\bold{a}'}{\max}Q_\phi(\bold{s}',\bold{a}')=\log\int\exp(Q_\theta(\bold{s}',\bold{a}'))d\bold{a}'\]여기서 최적의 정책은 앞서 살펴본 것처럼 \(\pi(\bold{a}\mid\bold{s})=\exp(Q_\phi(\bold{s},\bold{a})-V(\bold{s}))=\exp(A(\bold{s},\bold{a}))\)이 되고, Soft Q-Learning이 도출된다.
Soft Q-Learning을 유도하는 다른 방법은 Value Iteration에서 Q-Learning으로 넘어가는 방법을 그대로 적용하는 것이다. 먼저, 아래와 같이 backward message를 구할 수 있음을 떠올리자.
\[\text{For}\enspace t=T-1\enspace\text{to}\enspace1:\\ \quad Q_t(\bold{s}_t,\bold{a}_t)\leftarrow r(\bold{s}_t,\bold{a}_t)+\mathbb{E}[V_{t+1}(\bold{s}_{t+1})]\\ \quad V_t(\bold{s}_t)\leftarrow\text{softmax}_\bold{a_t}Q_t(\bold{s}_t,\bold{a}_t)\]이제 \(Q\)함수를 근사하기 위해 \(Q_\theta\)를 도입하고 TD방법을 사용해서 루프 안에 있는 첫번째 줄을 바꿔주면 똑같은 알고리즘인 Soft Q-Learning을 유도할 수 있다. 물론, 이 알고리즘을 바로 사용할 수 있는 것은 아니다. Softmax부분을 계산하기 위해서 적분이 들어갈 뿐 아니라 정책에서 행동을 샘플하는 것 모두 쉬운 일은 아니기 때문이다. Soft Q-Learning 논문에서는 이 문제를 importance sampling과 Stein variational gradient descent을 사용하여 해결하려고 하였다.
Deep Q network를 사용하는 만큼 Target network 등 분산을 줄이려는 기법을 가미하면 알고리즘이 완성된다.
Maximum Entropy Policy Gradients
다음으로, Evidence Lower Bound를 variational distribution \(q(\tau)\)에 대해서 최대화하는 방법을 생각할 수 있다. 위에서 정의한 문제대로 생각하면 \(q(\tau)\)는 \(q(\bold{s}_1),q(\bold{s}_{t+1}\mid\bold{s}_t,\bold{a}_t),q(\bold{a}_t\mid\bold{s}_t)\)로 나눌 수 있는데, 초기 상태분포와 전이분포는 \(p(\bold{s}_1),p(\bold{s}_{t+1}\mid\bold{s}_t,\bold{a}_t)\)와 동일하게 두기로 했으므로 우리가 바꿀 수 있는 것은 \(q(\bold{a}_t\mid\bold{s}_t)\)밖에 없다. 즉, 정책 \(q(\bold{a}_t\mid\bold{s}_t)\)를 바꾸어가면서 ELBO를 최대화할 수 있는 것이다. Policy Gradient와 같은 접근법이다! 자연스럽게 ELBO식을 목적함수로 정하고 \(q_\theta(\bold{a}_t\mid\bold{s}_t)\)를 파라미터 \(\theta\)를 가지는 뉴럴넷으로 모델링한 뒤, \(\theta\)를 바꿔가면서 최적화를 진행하자.
\[J(\theta)=\sum\limits^T_{t=1}\mathbb{E}_{(\bold{s}_t,\bold{a}_t)\sim q(\bold{s}_t,\bold{a}_t)}[r(\bold{s}_t,\bold{a}_t)-\mathcal{H}(q_\theta(\bold{a}_t\mid\bold{s}_t))]\]이제 Policy Gradient와 비슷하게 \(J\)의 그래디언트를 구하자.
\[\nabla_\theta J(\theta)=\sum\limits^T_{t=1}\nabla_\theta\mathbb{E}_{(\bold{s}_t,\bold{a}_t)\sim q(\bold{s}_t,\bold{a}_t)}[r(\bold{s}_t,\bold{a}_t)+\mathcal{H}(q_\theta(\bold{a}_t\mid\bold{s}_t))]\\ =\sum\limits^T_{t=1}\mathbb{E}_{(\bold{s}_t,\bold{a}_t)\sim q(\bold{s}_t,\bold{a}_t)}\bigg[\nabla_\theta\log q_\theta(\bold{a}_t\mid\bold{s}_t)\bigg(\sum\limits^T_{t'=t}r(\bold{s}_{t'},\bold{a}_{t'})-\log q_\theta(\bold{a}_{t'}\mid\bold{s}_{t'})-1\bigg)\bigg]\\ =\sum\limits^T_{t=1}\mathbb{E}_{(\bold{s}_t,\bold{a}_t)\sim q(\bold{s}_t,\bold{a}_t)}\bigg[\nabla_\theta\log q_\theta(\bold{a}_t\mid\bold{s}_t)\bigg(\sum\limits^T_{t'=t}r(\bold{s}_{t'},\bold{a}_{t'})-\log q_\theta(\bold{a}_{t'}\mid\bold{s}_{t'})-b(\bold{s}_{t'})\bigg)\bigg]\]Policy Gradient에서 상태에만 의존하는 함수를 더하거나 빼도 그래디언트 추정량이 불편이기 때문에 엔트로피를 미분한 것에서 나온 -1을 함수 \(b(\bold{s}_{t'})\)로 바꿀 수 있는 것이다. 잘 보면 그래디언트가 일반 Policy Gradient와 비슷한 것을 알 수 있다. 유일한 차이점은 매 \(t'\)시점마다 보상에 더해지는 \(-\log q_\theta(\bold{a}_{t'}\mid\bold{s}_{t'})\)항이다. 현재 정책 하에서 해당 행동의 로그확률을 빼준다는 것인데, 결국은 정책의 엔트로피를 최대화하기 위해 존재하는 항이다.
Maximum Entropy Actor-Critic
마지막으로 Actor-Critic기법에 확률적 추론을 적용해보자. 먼저, MaxEnt PG방법에서 찾는 \(q(\bold{a}_t\mid\bold{s}_t)\)의 이론적인 최적값은 아래와 같다는 것을 생각해보자.
\[q^\star(\bold{a}_t\mid\bold{s}_t)=\frac{1}{Z}\exp\bigg(\mathbb{E}_{q(\bold{s}_{t+1:T},\bold{a}_{t+1:T}\mid\bold{s}_t,\bold{a}_t)}\bigg[\sum\limits^T_{t'=t}\log p(\mathcal{O}_{t'}\mid\bold{s}_{t'},\bold{a}_{t'})-\sum\limits^T_{t'=t+1}\log q(\bold{a}_{t'}\mid\bold{s}_{t'})\bigg]\bigg)\]\(D_{\text{KL}}(q(\tau)\lVert p(\mathcal{O}_{1:T},\tau))=0\)으로 만들어주는 \(q({\tau})\)의 표현을 쓴 다음 상태 \(\bold{s}_t\)에 조건식을 취하면 행동 \(\bold{a}_t\)는 이전 상태에는 독립이지만 미래 상태/행동에는 의존적이게 되기 때문이다. 이제 기댓값 안에 들어가있는 부분에 대해서 \(t\)시점만 밖으로 빼면 아래와 같은 표현을 얻을 수 있다.
\[\log p(\mathcal{O}_t\mid\bold{s}_t,\bold{a}_t)+\mathbb{E}_{q(\bold{s}_{t+1}\mid\bold{s}_t,\bold{a}_t)}\bigg[\mathbb{E}\bigg[\sum\limits^T_{t'=t+1}\log p(\mathcal{O}_{t'}\mid\bold{s}_{t'},\bold{a}_{t'})-\log q(\bold{a}_{t'}\mid\bold{s}_{t'})\bigg]\bigg]\]이제 \(V\)와 \(Q\)를 정의하자.
\[V(\bold{s}_t)=\mathbb{E}\bigg[\sum\limits^T_{t'=t+1}\log p(\mathcal{O}_{t'}\mid\bold{s}_{t'},\bold{a}_{t'})-\log q(\bold{a}_{t'}\mid\bold{s}_{t'})\bigg]\\ =\mathbb{E}_{q(\bold{a}_t\mid\bold{s}_t)}[\log p(\mathcal{O}_t\mid\bold{s}_t,\bold{a}_t)-\log q(\bold{a}_t\mid\bold{s}_t)+\mathbb{E}_{q(\bold{s}_{t+1}\mid\bold{s}_t,\bold{a}_t)}[V(\bold{s}_{t+1})]]\\ Q(\bold{s}_t,\bold{a}_t)=\log p(\mathcal{O}_t\mid\bold{s}_t,\bold{a}_t)+\mathbb{E}_{q(\bold{s}_{t+1}\mid\bold{s}_t,\bold{a}_t)}[V(\bold{s}_{t+1})]\]이렇게 정의하면 \(V(\bold{s}_t)=\mathbb{E}_{q(\bold{a}_t\mid\bold{s}_t)}[Q(\bold{s}_t,\bold{a}_t)-\log q(\bold{a}_t\mid\bold{s}_t)]\)라는 관계가 성립하고 \(q^\star\)는
\[q^\star(\bold{a}_t\mid\bold{s}_t)=\frac{\exp(Q(\bold{s}_t,\bold{a}_t))}{\log\int_\mathcal{A}\exp(Q(\bold{s}_t,\bold{a}_t))d\bold{a}_t}\]으로 표현할 수 있게 된다. 여기서 \(Q\)와 \(V\)는 모두 최적 정책 \(q^\star\)가 아닌 현재 정책에 대해서 정의되어 있으나, 수렴하게 되면 \(q=q^\star\)가 되면서 아래와 같이 된다.
\[V(\bold{s}_t)=\mathbb{E}_{q(\bold{a}_t\mid\bold{s}_t)}[Q(\bold{s}_t,\bold{a}_t)-\log q(\bold{a}_t\mid\bold{s}_t)]\\ =\mathbb{E}_{q(\bold{a}_t,\bold{s}_t)}\bigg[Q(\bold{s}_t,\bold{a}_t)-Q(\bold{s}_t,\bold{a}_t)+\log\int_\mathcal{A}\exp(Q(\bold{s}_t,\bold{a}_t))d\bold{a}_t\bigg]\\ =\log\int_\mathcal{A}\exp(Q(\bold{s}_t,\bold{a}_t))d\bold{a}_t\]앞에서 보았던 soft \(V\)함수를 만든 것이다. 방금 뭘 한거냐면, backward message passing을 통해서 \(Q\)와 \(V\)를 찾아 이론적인 최적 정책을 찾을 수 있다는 것을 보인 것이다. Actor-Critic알고리즘을 만드는 데 한발짝 다가선 것이다.
하지만 실제로 KL발산을 0으로 만들 수 있는 정책을 실용적으로 만들 수 없을 것이다. 만약 어떠한 모델 family안에 있는 정책만 찾을 수 있다고 한다면, 한 시점 \(t\)에 대해서 ELBO를 구한 뒤에 그래디언트를 사용하여 최적화를 진행할 수 있을 것이다. 그럼 \(q(\bold{s}_t\mid\bold{a}_t)\)에 대해서 ELBO를 써보자.
\[\mathbb{E}_{\bold{s}_t\sim q(\bold{s}_t)}[\mathbb{E}_{\bold{a}_t\sim q(\bold{a}_t\mid\bold{s}_t)}[Q(\bold{s}_t,\bold{a}_t)-\log q(\bold{a}_t\mid\bold{s}_t)]]\]이 표현의 그래디언트는 아래와 같다.
\[\mathbb{E}_{\bold{s}_t\sim q(\bold{s}_t)}[\mathbb{E}_{\bold{a}_t\sim q(\bold{a}_t\mid\bold{s}_t)}[\nabla\log q(\bold{a}_t\mid\bold{s}_t)(Q(\bold{s}_t,\bold{a}_t)-\log q(\bold{a}_t\mid\bold{s}_t)-b(\bold{s}_t))]]\]앞서 MaxEnt PG에서 살펴본 바와 동일하다. 몬테카를로 방법인 \(r\)대신 \(Q\)함수를 썼다는 점이 다른 점이다. 그 말은 전통적인 Actor-Critic의 soft버전으로 받아들일 수 있다는 뜻이다. MaxEnt PG보다 변동성이 적은 방법이다. 여기서 좀 더 실용적인 알고리즘으로 만들기 위해서 \(Q\)와 \(V\)함수를 학습하는 절차를 포함시킨다. 파라미터를 활용해서 \(Q_\phi\)와 \(V_\psi\)라고 쓴다면,
\[\mathcal{E}(\phi)=\mathbb{E}_{(\bold{s}_t,\bold{a}_t)\sim q(\bold{s}_t,\bold{a}_t)}\Big[\Big(r(\bold{s}_t,\bold{a}_t)+\mathbb{E}_{q(\bold{s}_{t+1}\mid\bold{s}_t,\bold{a}_t)}[V_\psi(\bold{s}_t)]-Q_\phi(\bold{s}_t,\bold{a}_t)\Big)^2\Big]\\ \mathcal{E}(\psi)=\mathbb{E}_{\bold{s}_t\sim q(\bold{s}_t)}\Big[\Big(\mathbb{E}_{\bold{a}_t\sim q(\bold{a}_t\mid\bold{s}_t)}[Q_\phi(\bold{s}_t,\bold{a}_t)-\log q(\bold{a}_t\mid\bold{s}_t)]-V_\psi(\bold{s}_t)\Big)^2\Big]\]이 두 목적함수를 최소화하는 \(\phi\)와 \(\psi\)를 찾으면 될 것이다. 물론 여기에서도 target network기법을 사용하여 target network를 고정할 수 있겠다. 이 논문에서는 \(V_\psi\)를 따로 학습하는 방법이 나와 있는데, 해당 알고리즘 논문의 최신판에서는 \(Q_\phi\)만 학습하고 \(V\)는 \(V(\bold{s}_t)=\mathbb{E}_{q(\bold{a}_t\mid\bold{s}_t)}[Q(\bold{s}_t,\bold{a}_t)-\log q(\bold{a}_t\mid\bold{s}_t)]\)를 통해 \(Q_\phi\)로부터 계산해서 사용한다.
결국 structured variational approximation 프레임워크에서 Actor-Critic 방법을 만들었다. 이 알고리즘이 바로 Soft Actor Critic이다.
My conclusion
정말 길고 오래 걸린 논문 정리. 내용이 상당히 많지만 인사이트가 넘쳤다. 계속 읽으면서 알게 된 내용을 추가해야겠다. 완벽히 짚고 넘어가지 못한 세부적인 사항이 있을 수도 있으니 누구든 제발 틀린 것 있으면 피드백 주세요.
Reference
Soft Q Learning arxiv
Soft Actor-Critic arxiv
Levine at 2018 NIPS Infer2Control Video
University of Waterloo CS588 Lecture: Slides Video
UC Berkeley CS285 Lecture: Slides Video
Yuchen Lu’s Slides
Leave a comment